Modelamiento Bayesiano
Contenido
20. Modelamiento Bayesiano¶
En el enfoque Bayesiano:
La inferencia se realiza calculando la distribución a posteriori de los parámetros
Se modela la incerteza de los datos y parámetros con una distribución de probabilidad conjunta
\(\theta\) es un vector aleatorio cuya distribución de probabilidad se denomina a priori
El teorema de Bayes y la ley de probabilidades totales nos permiten escribir:
En el enfoque Bayesiano buscamos calcular la distribución a posteriori, la que se construye a partir de la función de verosimilitud, la distribución a priori y la evidencia, conocida también como la verosimilitud marginal de los datos.
20.1. El procedimiento de inferencia Bayesiana:¶
Definir la función de verosimilitud de los datos
Escoger una distribución a priori para los parámetros
Construir la distribución conjunta de datos y parámetros
Determinar la distribución a posteriori usando el Teorema de Bayes
Calcular estimadores puntuales
20.1.1. Estimadores puntuales¶
Moda a posteriori (MAP, maximum a posteriori)
para esta maximización no se requiere la evidencia pues esta no depende de \(\theta\). Además aplicando logaritmo podemos separar la verosimilitud de la distribución a priori:
Esperanza a posteriori
Varianza a posteriori
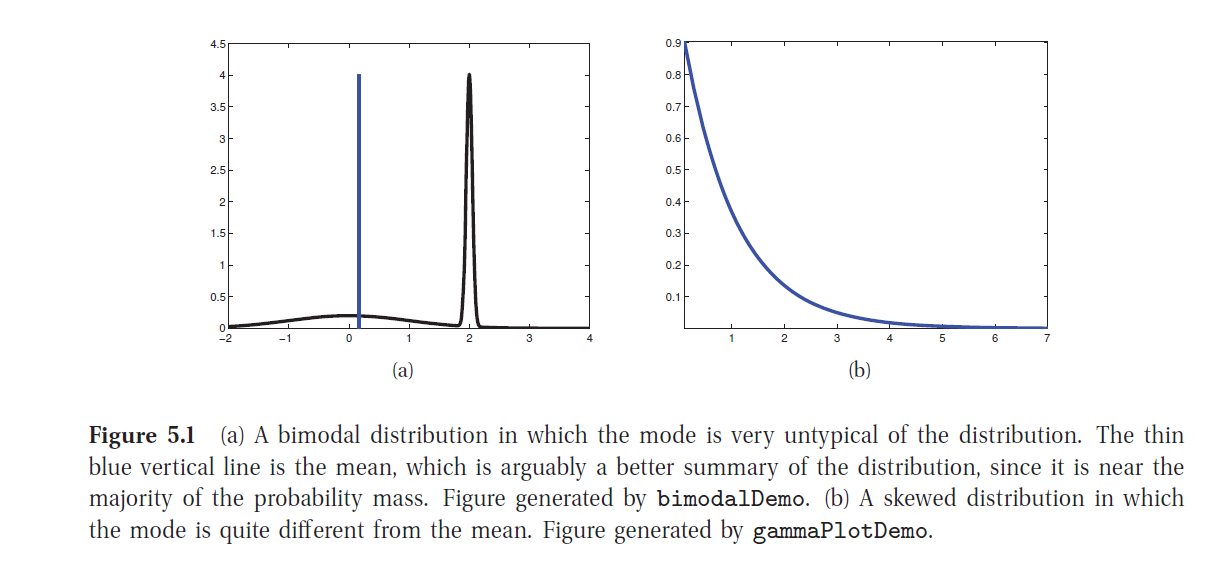
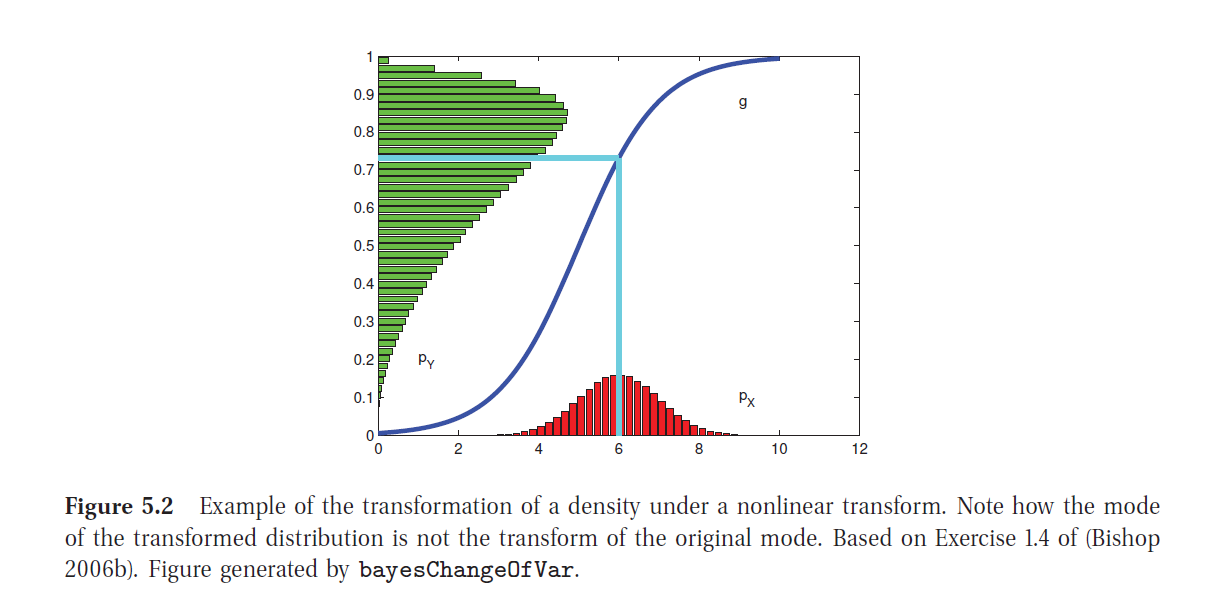
Algunas dificultades con MAP:
no es necesariamente representativa de la distribución a posteriori
no es invariante a reparametrizaciones de los parámetros
20.1.2. Intervalos de credibilidad:¶
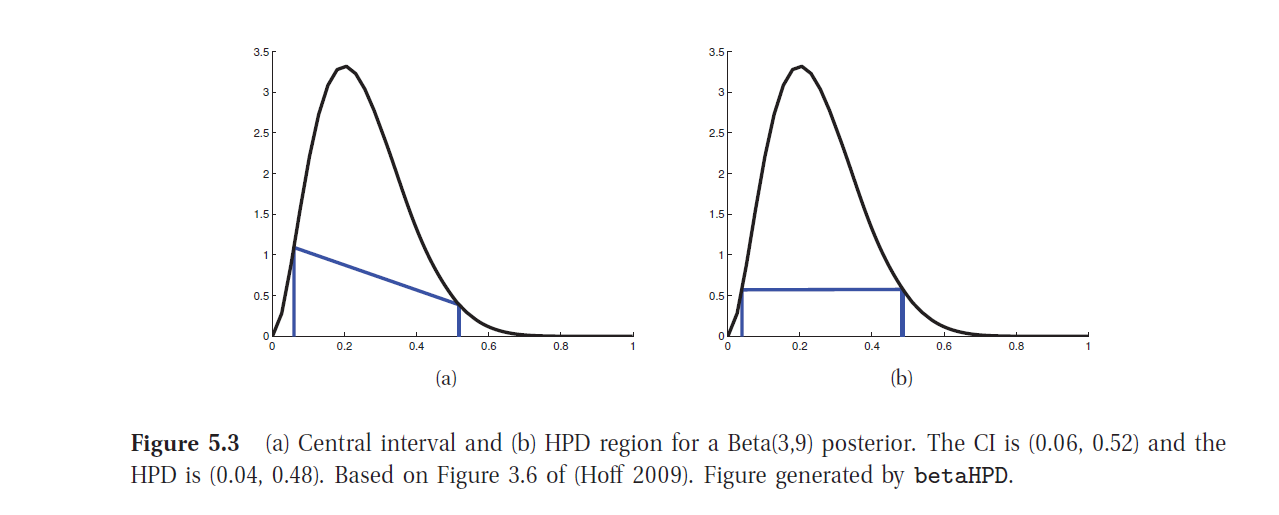
Intervalos centrales
Regiones de mas altas densidades a posteriori (HPD):
Sea \(p*\) un umbral para la distribución a posteriori que cumple que:
entonces se define:
Distribución Predictiva a posteriori
Nos permite predecir la probabilidad de ocurrencia de un nuevo dato \(x\)
20.2. Distribuciones naturales conjugadas¶
Una elección posible para las distribuciones a priori son aquellas que se conjugan con las funciones de verosimilitud, de manera que la distribución a posteriori es del mismo tipo que la distribución a priori pero con nuevos parámetros. Veamos algunos ejemplos.
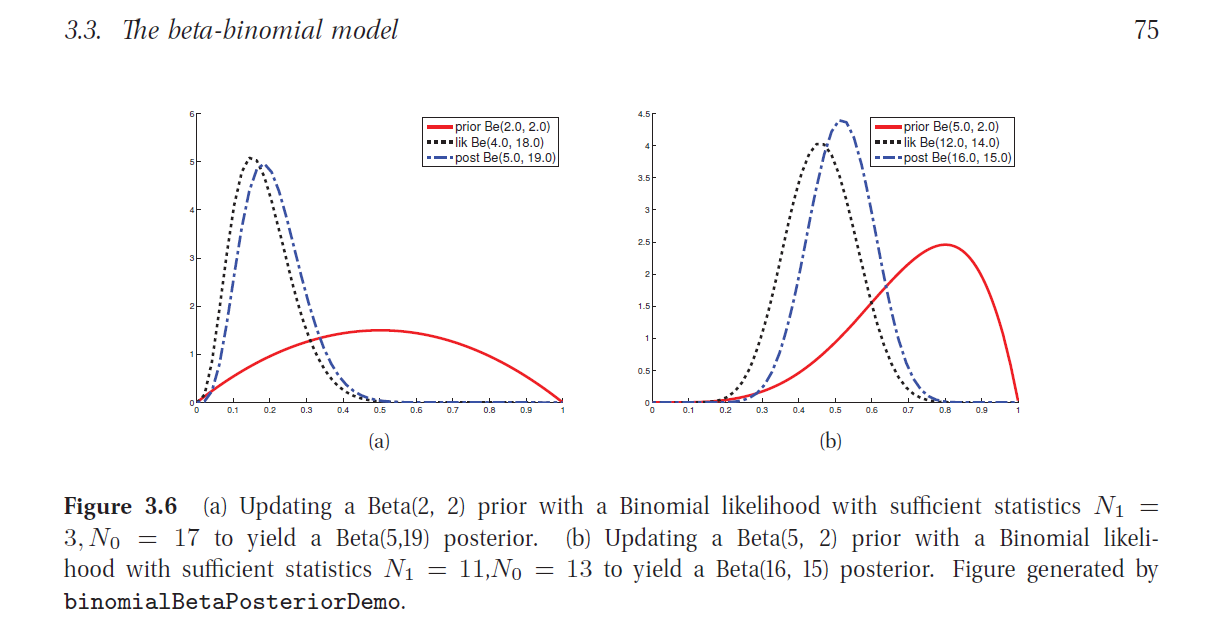
20.2.1. El modelo Beta-binomial¶
Consideremos el caso en que
Y por otra parte
suppressMessages(library(dplyr))
suppressMessages(library(plotly))
suppressMessages(library(ggplot2))
suppressMessages(library(rmarkdown))
vec <- seq(0,1,by=0.01)
params <- c(0.1,0.5,1,2,3,4,5,6,7,8)
pvec <- list()
for (i in 1:length(params))
for (j in 1:length(params)){
k = length(params)*(i-1) + j
pvec[[k]] <- dbeta(vec,params[i],params[j])
}
steps <- list()
fig <- plot_ly(width=600,height=600) %>% layout(title = "\n \n Densidad de Probabilidad Beta, a=0.1")
i=1
for (j in 1:length(params)){
k <- length(params)*(i-1) + j
fig <- add_lines(fig, x=vec, y=pvec[[k]],
visible=if ((i==1) && (j==1)) TRUE else FALSE,
mode='lines', line=list(color='blue'), showlegend=FALSE)
step <- list(args = list('visible', rep(FALSE, length(params))),
method='restyle',label=params[j])
step$args[[2]][j] <- TRUE
steps[[j]] <-step
}
fig <- fig %>% layout(sliders =
list( list(active=0,
currentvalue = list(prefix = "b: "),
pad = list(t=10),
steps=steps)))
fig
steps <- list()
fig <- plot_ly(width=600,height=600) %>% layout(title = "\n \n Densidad de Probabilidad Beta, a=1")
i=3
for (j in 1:length(params)){
k <- length(params)*(i-1) + j
fig <- add_lines(fig, x=vec, y=pvec[[k]],
visible=if ((i==3) && (j==1)) TRUE else FALSE,
mode='lines', line=list(color='blue'), showlegend=FALSE)
step <- list(args = list('visible', rep(FALSE, length(params))),
method='restyle',label=params[j])
step$args[[2]][j] <- TRUE
steps[[j]] <-step
}
fig <- fig %>% layout(sliders =
list( list(active=0,
currentvalue = list(prefix = "b: "),
pad = list(t=10),
steps=steps)))
fig
steps <- list()
fig <- plot_ly(width=600,height=600) %>% layout(title = "\n \n Densidad de Probabilidad Beta, a=8")
i=10
for (j in 1:length(params)){
k <- length(params)*(i-1) + j
fig <- add_lines(fig, x=vec, y=pvec[[k]],
visible=if ((i==10) && (j==1)) TRUE else FALSE,
mode='lines', line=list(color='blue'), showlegend=FALSE)
step <- list(args = list('visible', rep(FALSE, length(params))),
method='restyle',label=params[j])
step$args[[2]][j] <- TRUE
steps[[j]] <-step
}
fig <- fig %>% layout(sliders =
list( list(active=0,
currentvalue = list(prefix = "b: "),
pad = list(t=10),
steps=steps)))
fig
Algunas Propiedades de la Distribución Beta
i) \(moda(\theta)= \underset{\theta}{\operatorname{argmax}} f_{\theta}(\theta)\)
ii) \(\mathbb{E}(\theta) = \int_0^1 \theta f_{\theta}(\theta) d\theta\)
iii) \(\mathbb{V}(\theta) = \int_0^1 (\theta- \mathbb{E}(\theta)^2 f_{\theta}(\theta) d\theta\)
Nota:
y cumple:
Cálculo de la distribución a posteriori
donde
Es decir
Moda a posteriori (MAP):
Media a posteriori:
Varianza a posteriori
# parámetros a priori: Beta(5,2)
# parámetros likelihood: Beta(n1+1,n0+1)
# parametros a posteriori: Beta(5+n1,2+n0)
a=5
b=2
N=20
vec <- seq(0,1,by=0.01)
pvec0 <- dbeta(vec,a,b)
params <- seq(0,N,by=1)
params <- c(rbind(params,params))
aval <- list()
for (i in 1:length(params)){
aval[[i]] <-list(visible = FALSE,
y=dbeta(vec,params[i]+1,(N-params[i])+1),
z=dbeta(vec,params[i]+a,(N-params[i])+b))
}
steps <- list()
fig <- plot_ly(width=600,height=400) %>% layout(title = "\n \n Modelo Beta-Binomial", yaxis = list(range=c(0,8))) %>%
add_lines(x=vec,y=pvec0,line=list(color='red'),name= "Prior Beta(5,2)",showlegend=TRUE)
for (i in 1:N){
fig <- add_lines(fig,x=vec, y=aval[[2*i]]$y, visible = aval[[2*i]]$visible,
type = 'scatter', mode = 'lines', line=list(color='black',dash='dot'), name= "Likelihood")
fig <- add_lines(fig,x =vec, y=aval[[2*i]]$z ,visible = aval[[2*i]]$visible,
type = 'scatter', mode = 'lines', line=list(color='blue',dash='dash'),name = "Posterior")
step <- list(args = list('visible', rep(FALSE, 2*length(aval)+3)),
method = 'restyle',label=i)
step$args[[2]][2*i] = TRUE
step$args[[2]][2*i+1] = TRUE
step$args[[2]][1] = TRUE
steps[[i]] = step
}
length(steps)
# add slider control to plot
fig <- fig %>%
layout(sliders = list(list(active = 1,
currentvalue = list(prefix = "N_1: "),
steps = steps)))
fig
20.2.2. El modelo Dirichlet-multinomial¶
Consideremos el caso en que
De manera que la función de verosimilitud para n observaciones queda:
donde
Por otra parte, sea
En este caso, resulta que la distribución a posteriori es también Dirichlet:
Es decir
Ejemplo: diferencia de proporciones
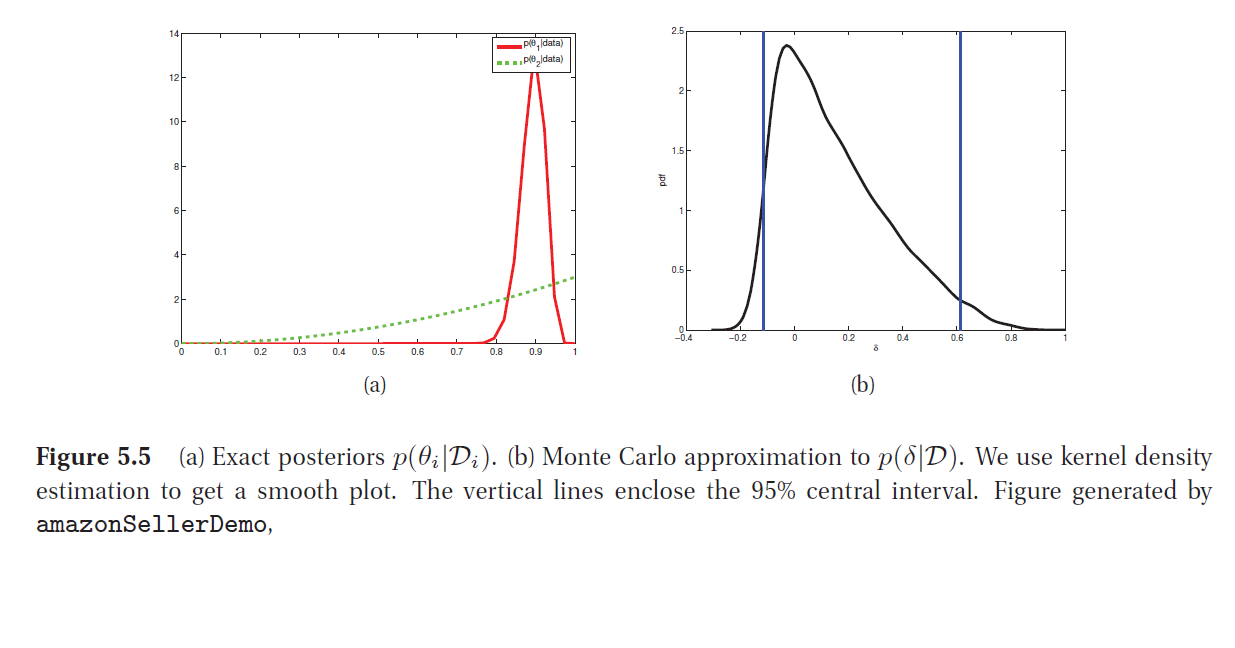
Supongamos que estamos interesados en comprar en una plataforma online, y hay dos vendedores que entregan el producto al mismo precio. El vendedor 1 tiene 90 evaluaciones positivas y 10 negativas. El vendendor 2 tiene 2 evaluaciones positivas y 0 negativas. ¿Cómo decidir cual comprar? En el enfoque bayesiano, el análisis es como sigue:
Sean \(\theta_1\) y \(\theta_2\) las confiabilidades reales de los dos vendedores. Como no tenemos mas información, vamos a considerar a priori uniformes: \(\theta_i \sim Beta(1,1)\) y entonces podemos usar el modelo beta-binomial. De manera que
En este caso $\(N_1 = 100, \,y_1 = 90,\qquad N_2 = 2,\, y_2 =2\)$
Entonces podemos calcular, para \(\delta = \theta_1 - \theta_2\):
Utilizando integración numérica se puede obtener que \(P(\delta > 0 \mid {\cal D})= 0.71\) y un intervalo central de la figura.
20.3. Enfoque Bayesiano para la Selección de modelos¶
Si disponemos de un conjunto de modelos entre los cuales elegir, por ejemplo una familia de distribuciones de probabilidad paramétricas de complejidad diferente, estamos en presencia del problema de selección de modelos.
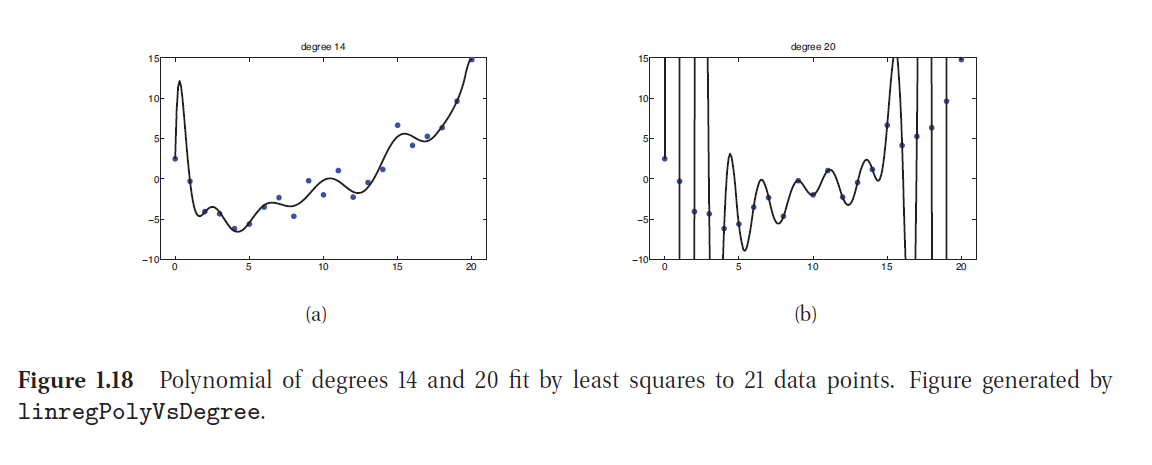
En el enfoque frecuentista, una manera de abordar esto es usar validación cruzada (cross-validation), para definir los errores para cada modelo y luego seleccionar el de mínimo error.
En el enfoque Bayesiano podemos hacer uso de la distribución predictiva de los datos o evidencia, por cada modelo \(m\) y escoger el de mayor probabilidad dados los datos \(\cal{D}\)
y entonces calculamos el modelo MAP:
Si consideramos una distribución a priori no informativa sobre los modelos (distribución uniforme), es decir \(p(m) \propto 1\), tenemos que:
llamada verosimilitud marginal o evidencia del modelo \(m\).
La navaja de Occam: (Bayesian Occam’s razor): el hecho de que la verosimilitud marginal considere la integración respecto de los parámetros impide que se maximice simplemente por aumentar el número de parámetros, con lo cual se previene el sobreajuste en la elección del modelo.
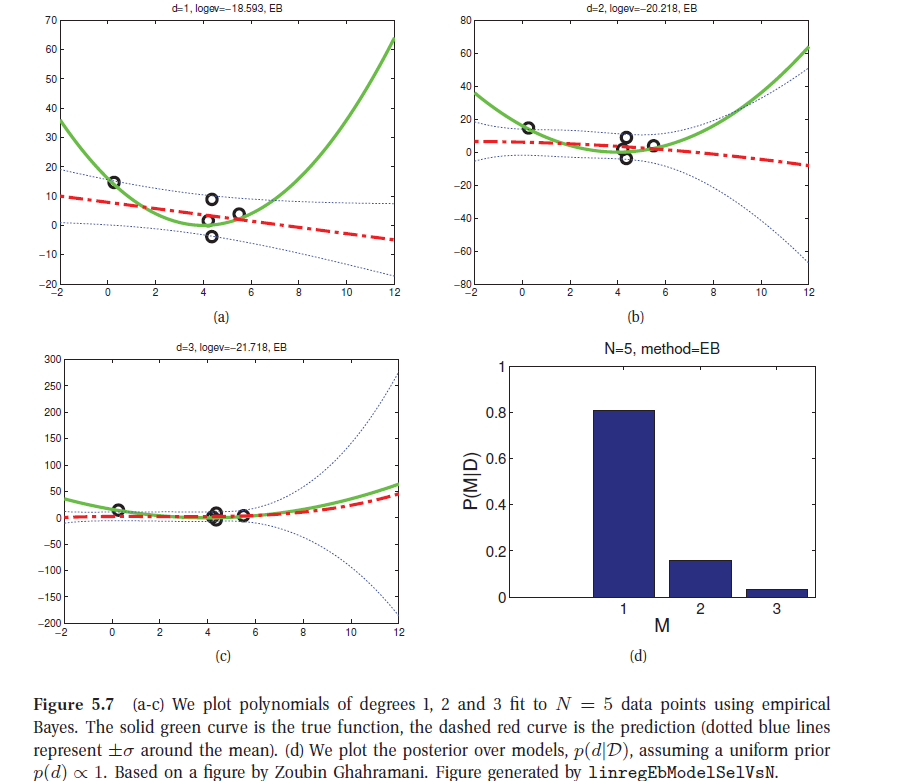
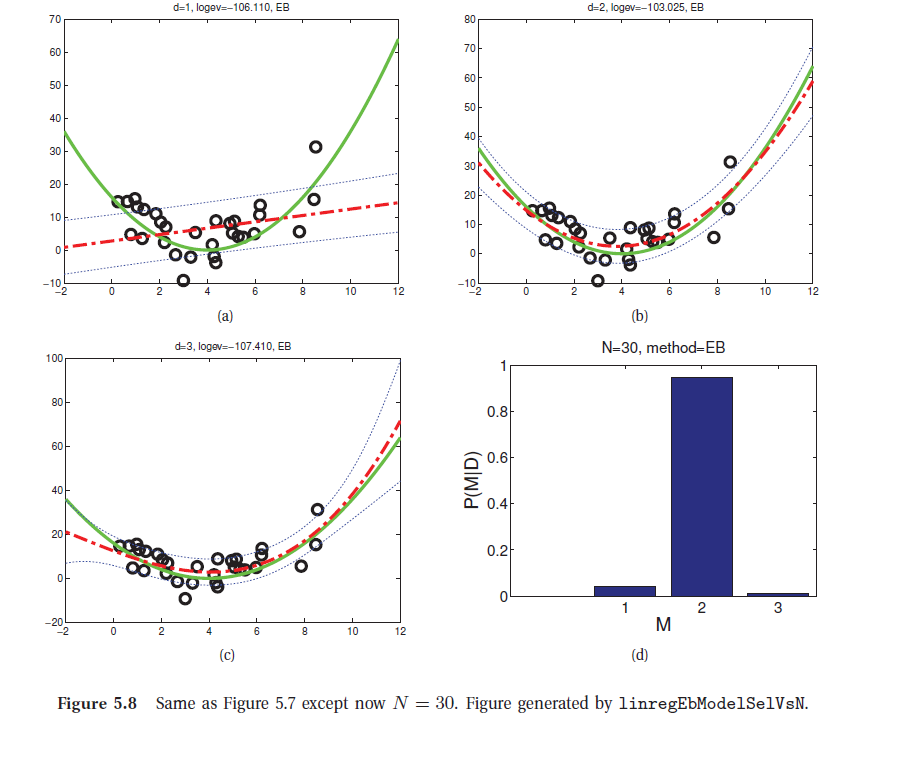
El cálculo de la verosimilitud marginal o evidencia es computacionalmente costoso en general y requiere utilizar técnicas del tipo Monte Carlo, salvo cuando tratamos con modelos de distribuciones conjugadas.
Veamos el caso del modelo Beta-Binomial:
En esta caso
Para el cálculo de \(p(\cal{D} \mid m)\), recordemos que en este caso la distribución a posteriori se distribuye \(Beta(a+N_1,b+N_0)\), entonces considerando Bayes tenemos:
20.3.1. Aproximación BIC del logaritmo de la verosimilitud marginal¶
Considerando que el cálculo de la verosimilitud marginal es en general costoso, Schwartz(1978) propone el Criterio de Información Bayesiano (BIC), como una aproximación del logaritmo de la verosimilitud marginal:
donde \(dof(\hat{\theta})\) son los grados de liberdad del modelo y \(\hat{\theta}\) es el estimador de máxima verosimilitud de \(\theta\).
De esta manera el BIC se puede interpretar como una versión del logaritmo de la verosimilitud penalizada por la complejidad del modelo.