Show code cell source
import holoviews as hv
hv.extension('bokeh')
hv.opts.defaults(hv.opts.Curve(width=500),
hv.opts.Scatter(width=500, size=4),
hv.opts.Histogram(width=500),
hv.opts.Slope(color='k', alpha=0.5, line_dash='dashed'),
hv.opts.HLine(color='k', alpha=0.5, line_dash='dashed'))
from bokeh.plotting import show
import pandas as pd
import numpy as np
import scipy.stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.stats.anova import anova_lm
from statsmodels.stats.outliers_influence import variance_inflation_factor
print(f"NumPy versión: {np.__version__}")
print(f"Scipy versión: {scipy.__version__}")
print(f"StatsModels versión: {sm.__version__}")


NumPy versión: 1.21.5
Scipy versión: 1.9.1
StatsModels versión: 0.13.2
16. Regresión Lineal Múltiple#
A continuación se generalizará el modelo de la lección anterior al caso multivariado, es decir cuando se quiere predecir una variable unidimensional \(Y\) a partir de una variable multidimensional \(X\). Podemos interpretar \(X\) como una tabla donde cada columna representa un atributo o característica en particular.
Veremos primero el formalismo matemático del método de Mínimos Cuadrados Ordinarios y luego como implementarlo en Python.
16.1. Derivación matemática del método de mínimos cuadrados ordinarios (OLS)#
Consideremos el dataset \(\{\bf{x_i},\) \(y_i\}_{i=1,\ldots,N}\) con observaciones donde \(y_i \in \mathbb{R}\) y \(\bf{x_i}\) \(\in \mathbb{R}^D\), con \(D>1\), y \(\bf{x_i}\) se considera dado. Queremos encontrar \(\bf b\) tal que:
Tal como en la lección anterior, empezamos escribiendo la suma de los errores cuadráticos:
Y queremos minimizar \(L\):
Nota
Desde un punto de vista estadístico, este criterio es razonable si las observaciones de entrenamiento (\(\bf{x_i}\), \(y_i\)) representan extracciones aleatorias independientes de su población. Pero, aunque las \(\bf{x_i}\) no se hayan extraído aleatoriamente, el criterio sigue siendo válido si las \(y_i\) son condicionalmente independientes dadas las entradas \(\bf{x_i}\).
Pero en este caso lo expresaremos en forma matricial:
donde
Luego podemos derivar e igualar a cero
para obtener las “ecuaciones normales”:
cuya solución es:
que se conoce como el estimador de mínimos cuadrados ordinarios (ordinary least squares, OLS) de \(\bf b\)
Advertencia
La solución de mínimos cuadrados sólo es válida si \(\bf X^T \bf X\) es invertible (no-singular).
Los coeficientes se interpretan como el efecto de cada predictor en la respuesta, si todas las demás predictores se mantienen constantes. Esto es a menudo ajustar para o controlar los otras predictores. Aquí es un ejemplo importante pare entender este punto (pon tu atención en las dos primeras cifras).
Nota
La solución que encontramos para el caso univariado es un caso particular de la solución de mínimos cuadrados ordinarios.
16.2. Perspectiva estadística de OLS#
16.2.1. Conexión con MLE#
En la demonstración arriba, no usamos ningún supuesto distribucional ni máxima verosimilitud (MLE) que esta diseñado para estimar parámetros. Vamos aplicarlo aquí!
Digamos que se tienen \(\{\bf x_i,\) \(y_i\}_{i=1,\ldots,N}\) observaciones de una variable dependiente unidimensional \(Y\) y una variable independiente D-dimensional \(X\), y \(X\) se considera dado. Asumiremos que las mediciones \(Y\) corresponden a una combinación aditiva de un modelo y ruido con distribución Gaussiana centrado en cero, es decir:
\(y_i = b_0 + \sum_{j=1}^D b_j x_{ij} + e_i = g_b(\bf{x_i}\)) + \(e_i\)
Y tenemos los siguientes supuestos importantes sobre \(e_i \):
Importante
Los \(e_i\) son i.i.d. Cada \(e_i \sim \mathcal{N}(0, \sigma^2)\), \(e_i\) es independiente de \(\bf{x_i}\), y los \(e_i\) son independientes entre sí mismos.
\(e_i=y_i - g_b(\bf x_i\))=\(y_i -\hat y_i\) también se llama residuo.
Así que
\(\text{dado } \bf x_i\), \(\qquad y_i - g_b(\)\(\bf x_i\)\() = e_i \sim \mathcal{N}(0, \sigma^2), \qquad y_i = g_b(\)\(\bf x_i\)\() + e_i\)
Aquí, no hacemos supuestos sobre la distribucion de \(\bf x_i\) (podría ser arbitrario), y consideramos que \( \bf x_i\) es dado. Así que:
\(y_i | \bf x_i\)\( \sim \mathcal{N}(g_b(\)\(\bf x_i\)\(), \sigma^2)\)
Los \(y_i\) tienen que ser i.i.d.? Los \(\bf x_i\) tienen que ser i.i.d.?
Consideramos la distribución condicional de \(y_i\) dado \(\bf x_i\) en todos pasos aquí bajo la perspectiva estadística:
\(f(y_i | \bf x_i) \) \(= \mathcal{N}(g_b(\bf x_i)\) \(, \sigma^2)\)
Por lo tanto, escribimos la verosimilitud usando la distribución condicional de \(y_i\):
\(\mathcal{L}(\bf b)\) \(= \prod_{i=1}^N f(y_i | \bf x_i; \bf b) \) \(= \prod_{i=1}^N \mathcal{N}(g_b(\bf x_i)\), \(\sigma^2)\)
La log-verosimilitud de \(\bf b\) es:
cuya solución de máxima verosimilitud se obtiene de:
Lo anterior es equivalente a:
donde \((\bf{y}-\bf{X}\bf{b})^T (\bf{y}-\bf{X}\bf{b})\) es equivalente a la suma de los errores cuadráticos que minimizamos antes, y sabemos la solución. Por lo tanto, el estimador de máxima verosimilitud de \(\bf b\) es:
Importante
La solución de mínimos cuadrados ordinarios es equivalente a la solución de máxima verosimilitud bajo los supuestos de observaciones i.i.d. y ruido gaussiano.
16.2.2. Propiedades estadísticas de OLS#
Algunas propiedades importantes del estimador de máxima verosimilitud (mínimos cuadrados) de \(\bf b\):
El estimador es insesgado.
Demostración
Definamos \(\bf e \) \(= (e_1, e_2, \ldots, e_N)^T\), donde \(\bf e\) \(\sim \mathcal{N_D}(\bf 0, \bf I \) \(\sigma^2)\).
Luego:
La varianza del estimador es \(\sigma^2 (\bf X^T X)^{-1}\).
Demostración
(Teorema de Gauss-Markov) El estimador de \(\bf b\) tiene la menor varianza entre todos los estimadores insesgados (Ver Hastie 3.2.2 en la bibliografía del curso).
16.2.3. Inferencia y tests de hipótesis para OLS#
Tenemos dos tipos de tests de hipótesis en OLS:
F-test para un modelo (o un conjunto de pendientes)
t-test para un coeficiente
16.2.3.1. F-test para un modelo#
Tenomos dos casos aquí:
1) F-test para el modelo completo (full F-test)
Comprobamos si todos las pendientes (de un modelo de regresión con D predictores) son iguales a cero, es decir:
¿Qué modelo corresponde a \(H_0\)? ¿Qué modelo corresponde a \(H_1\)?
Para entender F-statistic, empezamode de la identidad de la suma de cuadrados:
(A veces, también se utiliza SSR para referirse a SSE, donde R significa residual (residuo). La abreviatura debe entenderse en su contexto.)
Queremos tener SSE=\(\sum\limits_{i=1}^{N}(y_i - \hat{y_i})^2\) pequeño y SSR=\(\sum\limits_{i=1}^{N}(\hat{y_i} - \bar{y})^2\) grande. En primer lugar, escribimos SSR como la resta de SST y SSE:
donde SST puede entenderse como el error (o residuo) del modelo reducido con sólo la intersección. Así que tenemos la resta de errores (residuos) de dos modelos.
Además, como cada suma de cuadrados tiene asociado algún grado de libertad (degree of freedom df), los dividimos por sus df:
Por tanto,
Construimos F-statistic por división:
donde \( f \sim F_{D,N-D-1}\).
Si queremos \(SSE\) pequeño y \(SSR\) grande, ¿qué queremos en \(f\)?
Al final, tenemos la tabla del análisis de varianza en la regresión múltiple:
Source |
Sum of Squares |
df |
Mean Squares |
F |
|---|---|---|---|---|
Regression |
SSR=\(\sum\limits_{i=1}^{N}(\hat{y_i} - \bar{y})^2\)=SST-SSE=\(\sum\limits_{i=1}^{N}(y_i - \bar{y})^2 - \sum\limits_{i=1}^{N}(y_i - \hat{y_i})^2\) |
D |
MSR=\(\frac{SSR}{D}\) |
\(f=\frac{MSR}{MSE}=\cfrac{\frac{SST-SSE}{D}}{\frac{SSE}{N-D-1}}\) |
Error |
SSE=\(\sum\limits_{i=1}^{N}(y_i - \hat{y_i})^2\) |
N-D-1 |
MSE=\(\frac{SSE}{N-D-1}\) |
|
Total |
SST=\(\sum\limits_{i=1}^{N}(y_i - \bar{y})^2\) |
N-1 |
¿Ha encontrado alguna similitud con la prueba ANOVA?
Ahora, identificamos F-test en Python y R (usando un ejemplo que vamos a estudiar en breve):
Python:
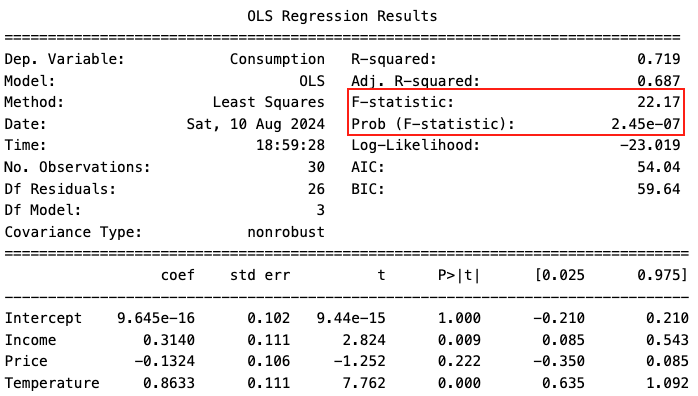
R:
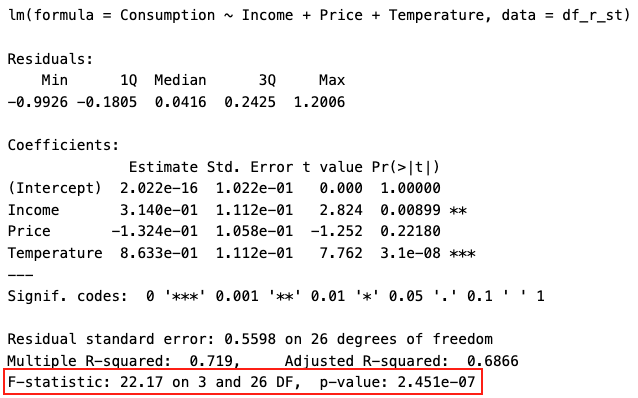
Prob(F-statistic) o p-value corresponde al p-value del F-test del modelo completo. Significa que la probabilidad de tener un valor tan extremo como el valor que tenemos de F-estadístico es de 2,45e-07 (muy pequeño) bajo \(H_0\). Rechazamos \(H_0\). Tenemos evidencia de que el modelo de regresión difiere de un modelo de sólo intersección (intercept-only model).
Residual standard error en R corresponde a raíz cuadrada positiva del mean squared error MSE (error cuadrático medio).
Informamos el F-test así:
\(F\)(3, 26) = 22.17, \(p\) < .001
2) F-test para un modelo reducido (partial F-test / generalized linear F-test)
Comprobamos si un subconjunto de las pendientes (de un modelo de regresión con \(D\) predictores) son cero. Este test es una generalización de full F-test y es útil para comparar dos modelos de regresión en los que uno está anidado (“nested”) en el otro (i.e., que tiene un subconjunto de predictores del otro).
Por ejemplo, si nos interesan dos pendientes \(b_2\) y \(b_3\) de un modelo con \(D\)=3, las hipótesis son:
Y tenemos dos modelos:
Modelo reducido (\(H_0\)): \(\hat{y}_i^{Red} = b_0 + b_1 x_{i1}\)
Modelo full (\(H_1\)): \(\hat{y}_i^{Full} = b_0 + b_1 x_{i1} + b_2 x_{i2}+ b_3 x_{i3}\)
En general, definimos:
y
Construimos F-statistic:
donde
Y seguimos el mismo procedimiento del caso 1) para comprobar la hipótesis.
16.2.3.2. T-test para un coeficiente#
Comprobamos si uno de los coeficientes (intersección o pendiente de un modelo de regresión) es cero, es decir:
donde \(i=0, 1, ..., D\).
La siguiente parte de la derivación de t-test es opcional.
Dado los siguientes:
El valor esperado y la varianza de \(\bf{\hat b}\) (ver arriba)
\(\bf{\hat b} = (\bf X^T \bf X)^{-1} \bf X^T \bf y\) donde \(\bf X\) es dado y se considera como constante, y \(f(y_i|\bf{x_i}\)) \(\sim \cal N(g_b(\bf{x_i}),\) \(\sigma^2), \forall i\)
(También podemos usar la propiedad “Asintóticamente Normal” del estimador de máxima verosimilitud y consideramos los casos de tamaño grande.)
Así que tenemos:
Con respecto al estimador de la varianza \(\hat \sigma^2\), típicalmente se estima por:
(Usamos \(N−D−1\) en lugar de \(N\) en el denominador para tener un estimador insesgado de \(\sigma^2\).)
Por otro lado el estimador de la varianza cumple:
Así que:
Con estos tenemos lo necesario para formular tests de hipótesis sobre \(\bf{\hat b}\).
(La seguiente parte es importante)
Ahora, identificamos t-test en Python y R (usando un ejemplo que vamos a estudiar en breve):
Python:

R:
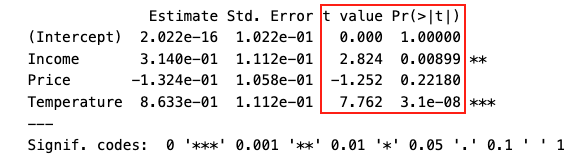
P>|t| o Pr(>|t|) corresponde a los p-values de los t-tests. Cada uno significa que la probabilidad de tener un valor tan extremo como el valor que tenemos de t de un coeficiente bajo su \(H_0\). Si \(p<\alpha\) (normalmente, si \(p<0.05\)), rechazamos el \(H_0\) y tenemos evidencia de que el coeficiente no es cero, y decimos que este coeficiente es significativo.
16.3. Supuestos y requisitos para regresicón lineal#
Requisitos:
\(Y\) es continuo.
\(X\) no tiene el problema de multicolinealidad (multicollinearity), si el valor o la significancia de los coeficientes de los coeficientes te importan.
La multicolinealidad sucede cuando uno o más de los predictores están altamente correlacionados con combinaciones lineales de otros predictores. Cuando esto sucede, el estimador OLS de los coeficientes tiende a ser muy impreciso, tiene una alta varianza (error estándar) y alto p-value, incluso si el tamaño de la muestra es grande.
(Esto está relacionado con \((\bf X^TX)^{-1}\) cuando estimamos \(\bf b\))
Supuestos (“LINE” usando íngles):
Linear function: La relación entre \(X\) e \(Y\) es lineal: la media de la respuesta \(E[y_i|\bf{x_i}]\), en cada conjunto de valores de los predictores \(\bf{x_i}\) \((x_{i1}, x_{i2} ... x_{iD})\), es una función lineal de los predictores.
Esto equivale a tener media 0 sobre los residuos \(e_i\) en cada \(\bf{x_i}\).
Independent: Los errores \(e_i\) son independientes entre sí mismos, y cada error \(e_i\) es independiente de \(\bf{x_i}\)
Normally distributed: Cada error \(e_i \sim \mathcal{N}(0, \sigma^2)\). Es decir, cada error \(e_i\) en cada \(\bf{x_i}\) tiene una distribución normal con media 0.
Equal variances: Los errores tienen la misma varianza \(\sigma^2\). Es decir, Los errores \(e_i\) en cada \(\bf{x_i}\) tienen la misma varianza \(\sigma^2\).
Estos cuatro supuestos son equivalentes a esto:
Cada error \(e_i \sim \mathcal{N}(0, \sigma^2)\), \(e_i\) es independiente de \(\bf{x_i}\), y los errores \(e_i\) son independientes entre sí mismos. Es decir, \(\bf e \sim \mathcal{N_D}(0, \bf{I}\) \(\sigma^2)\).
¿Cómo examinar estos supuestos y supuestos?
1) Antes de ajustar el modelo, usamos:
Conocimiento de los datos:
\(Y\) tiene que ser continuo.
Si cada persona se recopiló varias observaciones (a través del tiempo o de las tareas), el supuesto de independencia podría ser violado (supuesto I).
Si se viola, hay varias optiones: agrega datos de cada persona, usa mixed-effects models, o autoregressive models.
Gráfica de dispersión (scatter plot) entre \(Y\) y cada predictor \(X_{.k}\): sería ideal tener una relación lineal con un pendiente distinta de cero (aproximadamente) (supuesto L)
Ojo: A veces, aunque \(X_{.k}\) y \(Y\) no tiene una clara relación (p.ej. pendiente 0) según el coeficiente de correlación o gráfica de dispersión, \(X_{.k}\) puede ser un predictor significativo. ¿Por qué? Aquí es un ejemplo importante pare entender este punto (pon tu atención en las dos primeras cifras).
Si se viola, hay varias optiones: no usa el predictor, tranforma el predictor (e.g., \(x^2\) para hacer regresión polinómica), o transforma la respuesta (e.g., \(logY\)), etc.
Matriz de correlación:
Si la multicolinealidad te importa, evite usar predictores que estén altamente correlacionados (e.g., Pearson \(r\) > 0.9) al mismo tiempo en el modelo.
2) Después de ajustar el modelo, examinamos los residuos con:
Gráfica de dispersión entre \(e_{i}\) y \(\hat y_i\):
El promedio (vertical) de los residuos en cada valor de \(\hat y_i\) permanece cerca de 0 a medida que escaneamos el gráfico de izquierda a derecha. (supuestos L y I)
La dispersión (vertical) de los residuos permanece aproximadamente igual (constante) a medida que escaneamos el gráfico de izquierda a derecha (supuesto E)
No hay hay puntos excesivamente periféricos (outlying).
Si se violan, hay varias optiones: tranforma el predictor (e.g., \(x^2\)), transforma la respuesta (e.g., \(logY\)), etc.
Q-Q plot, (histograma/plot de densidad), Shapiro-Wilk test (normalmente para N \(<\) 50) o Kolmogorov–Smirnov test (normalmente para N \(\geq\) 50):
Estos son para ver si los residuos siguien una distribución normal con la media 0.
[Optional] Gráfica de dispersión entre \(e_{i}\) y cada \(x_{.k}\):
El promedio (vertical) de los residuos en cada valor de \(x_{.k}\) permanece cerca de 0 a medida que escaneamos el gráfico de izquierda a derecha. (supuestos L y I)
La dispersión (vertical) de los residuos permanece aproximadamente igual (constante) a medida que escaneamos el gráfico de izquierda a derecha (supuesto E)
Si se violan, hay varias optiones: tranforma el predictor (e.g., \(x^2\)), transforma la respuesta (e.g., \(logY\)), etc.
[Optional] Gráfica de dispersión entre \(e_{i}\) y tiempo o espacio:
Esto es relevante solo si los datos se recogieron en el tiempo (o espacio) para la misma unidad.
No hay un patrón no aleatorio sistemático (esto afirma el supuesto i).
Si se viola, hay varias optiones: mixed-effects models, o autoregressive models.
Si el problema de multicolinealidad te importa, tienes que examinar VIF para regresión lineal multiple:
Variance inflation factor / VIF (opcional / depende):
\(\displaystyle VIF_k = \frac{1}{1-R_k^2}\) donde \(R_k^2\) es el \(R^2\) de una regresión donde uno predice \(X_{.k}\) por los otros predictores \(X_{.j}\). La regla general es que el VIF superior a 5 sugiere multicolinealidad y justifica una mayor investigación, mientras que el VIF superior a 10 es signo de multicolinealidad grave que requieren corrección.
Otros puntos:
Si la varianza de los residuos no son iguales o tiene patrón:
Puedes considerar tranforma el predictor (e.g., \(x^2\)) y transforma la respuesta (e.g., \(logY\))
Es posible que faltan predictores
Puedes intentar Mínimos Cuadrados Ponderados (Weighted Least Squares, WLS), que es un tipo de Robust Regression.
WLSestá implementado enstatsmodels.
En caso de puntos influyentes:
Un punto de datos es influyente (influential) si influye indebidamente en cualquier parte del análisis de regresión, como las respuestas predichas, los coeficientes de pendiente estimados o los resultados de las pruebas de hipótesis.
Hay dos casos para ser datos influyentes:
Si la respuesta es muy diferente del valor predicho - valor atípico (outlier)
Si los valores de predictor(es) son extremos - puntos con alto apalancamiento (high leverage)
No todos valores atípicos o puntos con alto apalancamiento son influyentes. Para identificar datos influyentes, puedes consultar este material.
Si exiten puntos influyentes, hay varias opciones:
Winsorizing las variables y describa en sus informes
Elimina estos puntos, pero solo si tienes una razón buena y objetiva. Si eliminas cualquier dato, justifique y describa en sus informes.
Si no estas seguro, analiza los datos dos veces, una vez con estos punto y una vez sin ellos, e informe de los resultados de ambos análisis.
Utiliza Robust Regression.
Advertencia
No elimine puntos de datos solo porque no se ajustan a su modelo de regresión preconcebido.
Veamos cómo examinar estos supuestos en un ejemplo.
16.4. Un pipeline básico de modelamiento con regresión#
16.4.1. Pregunta de investigación#
(También puedes generar la pregunta de investigación durante el análisis de datos exploratorios.)
Tenemos una “teoría” / explicación hipotética de consumo de helado a priori y preguntamos:
P1: ¿Existe una relación lineal entre el consumo de helados y la combinación del ingreso, la temperatura y el precio? (O podemos explicar el consumo de helados por el ingreso, la temperatura y el precio juntos?)
P2: ¿Qué variable es más importante para explicar el consumo de helados?
Según las preguntas, nos importan el valor o la significancia de los coeficientes. Esto es diferente que una pregunta como “¿Cuál es el mejor modelo para explicar/predecir el consumo?”
16.4.2. Inspección, preprocesamiento y análisis exploratorio de datos#
Tenemos un conjunto de datos donde cada fila corresponde a un día, y las columnas corresponden a:
consumo de helados promedio (pintas per capita)
ingreso familiar promedio (dolares)
temperatura promedio (grados Fahrenheit)
precio promedio de los helados (dolares)
df = pd.read_csv('data/ice_cream.csv')
display(df.head())
df.describe()
| Consumption | Income | Price | Temperature | |
|---|---|---|---|---|
| 0 | 0.386 | 78 | 0.270 | 41 |
| 1 | 0.374 | 79 | 0.282 | 56 |
| 2 | 0.393 | 81 | 0.277 | 63 |
| 3 | 0.425 | 80 | 0.280 | 68 |
| 4 | 0.406 | 76 | 0.272 | 69 |
| Consumption | Income | Price | Temperature | |
|---|---|---|---|---|
| count | 30.000000 | 30.00000 | 30.000000 | 30.000000 |
| mean | 0.359433 | 84.60000 | 0.275300 | 49.100000 |
| std | 0.065791 | 6.24555 | 0.008342 | 16.421916 |
| min | 0.256000 | 76.00000 | 0.260000 | 24.000000 |
| 25% | 0.311250 | 79.25000 | 0.268500 | 32.250000 |
| 50% | 0.351500 | 83.50000 | 0.277000 | 49.500000 |
| 75% | 0.391250 | 89.25000 | 0.281500 | 63.750000 |
| max | 0.548000 | 96.00000 | 0.292000 | 72.000000 |
for col in df.columns:
print(col, "#unique:", df[col].nunique())
if df[col].nunique() < 6:
print(df[col].value_counts())
Consumption #unique: 28
Income #unique: 17
Price #unique: 14
Temperature #unique: 23
Sobre correlación (DV y IV, entre las IVs):
Pearson |r| >= 0.4 o Kendall |tau| >= 0.26 normalmente corresponde a una correlación moderada.
Si la multicolinealidad te importa, evite usar predictores que estén altamente correlacionados (e.g., Pearson
0.9) al mismo tiempo en el modelo.
df.corr() #pearson
| Consumption | Income | Price | Temperature | |
|---|---|---|---|---|
| Consumption | 1.000000 | 0.047935 | -0.259594 | 0.775625 |
| Income | 0.047935 | 1.000000 | -0.107479 | -0.324709 |
| Price | -0.259594 | -0.107479 | 1.000000 | -0.108206 |
| Temperature | 0.775625 | -0.324709 | -0.108206 | 1.000000 |
df.corr(method='kendall')
| Consumption | Income | Price | Temperature | |
|---|---|---|---|---|
| Consumption | 1.000000 | -0.039911 | -0.132322 | 0.644202 |
| Income | -0.039911 | 1.000000 | 0.004891 | -0.234053 |
| Price | -0.132322 | 0.004891 | 1.000000 | -0.084794 |
| Temperature | 0.644202 | -0.234053 | -0.084794 | 1.000000 |
pd.plotting.scatter_matrix(df, figsize=(6, 6))
array([[<AxesSubplot:xlabel='Consumption', ylabel='Consumption'>,
<AxesSubplot:xlabel='Income', ylabel='Consumption'>,
<AxesSubplot:xlabel='Price', ylabel='Consumption'>,
<AxesSubplot:xlabel='Temperature', ylabel='Consumption'>],
[<AxesSubplot:xlabel='Consumption', ylabel='Income'>,
<AxesSubplot:xlabel='Income', ylabel='Income'>,
<AxesSubplot:xlabel='Price', ylabel='Income'>,
<AxesSubplot:xlabel='Temperature', ylabel='Income'>],
[<AxesSubplot:xlabel='Consumption', ylabel='Price'>,
<AxesSubplot:xlabel='Income', ylabel='Price'>,
<AxesSubplot:xlabel='Price', ylabel='Price'>,
<AxesSubplot:xlabel='Temperature', ylabel='Price'>],
[<AxesSubplot:xlabel='Consumption', ylabel='Temperature'>,
<AxesSubplot:xlabel='Income', ylabel='Temperature'>,
<AxesSubplot:xlabel='Price', ylabel='Temperature'>,
<AxesSubplot:xlabel='Temperature', ylabel='Temperature'>]],
dtype=object)
Estandarización
Según P2, Nos intersa qué variable es más importante para explicar el consumo de helados, así que tenemos que estandarizar los predictores. Aquí estandarizamos la respuesta (Consumption) tambíen, aunque no es necesario.
Importante
La estandarización puede ser importante para evitar la multicolinealidad (o para tener coeficientes fiables) cuando el modelo tiene términos de interacción o polinómicos.
df_st = (df-df.mean())/df.std()
df_st.describe().round(2)
| Consumption | Income | Price | Temperature | |
|---|---|---|---|---|
| count | 30.00 | 30.00 | 30.00 | 30.00 |
| mean | 0.00 | 0.00 | 0.00 | -0.00 |
| std | 1.00 | 1.00 | 1.00 | 1.00 |
| min | -1.57 | -1.38 | -1.83 | -1.53 |
| 25% | -0.73 | -0.86 | -0.82 | -1.03 |
| 50% | -0.12 | -0.18 | 0.20 | 0.02 |
| 75% | 0.48 | 0.74 | 0.74 | 0.89 |
| max | 2.87 | 1.83 | 2.00 | 1.39 |
Nota
Si te interesa el rendimento de predición en datos nuevos (la generalización), considera dividir los datos en train set y test set.
Según la inspección de datos arriba:
“\(Y\) es continuo” se cumple.
Parece que podemos usar una relación lineal entre \(Y\) y \(X\).
Según la matriz de correlación, no detectamos un problema de multicolinealidad (aunque todavía es posible), y pudimos seguir adelante con los tres predictores.
16.4.3. Ajusta/entrena el modelo#
El problema a modelar es el siguiente:
Para ajustar este modelo de regresión lineal utilizaremos la librería statsmodels.formula.api en Python. Te permite escrbir la fórmula como “Consumption~Income+Price+Temperature” directamente. (Este es la forma por defecto en esta sesión).
model = smf.ols('Consumption~Income+Price+Temperature', data=df_st).fit()
La intersección (constante) \(b_0\) se añade automaticalmente por la función.
(También puedes usar la librería statsmodels, en particular, statsmodels.api y la clase OLS en Python.)
16.4.4. Examina F-test del modelo#
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Consumption R-squared: 0.719
Model: OLS Adj. R-squared: 0.687
Method: Least Squares F-statistic: 22.17
Date: Sat, 10 Aug 2024 Prob (F-statistic): 2.45e-07
Time: 19:13:10 Log-Likelihood: -23.019
No. Observations: 30 AIC: 54.04
Df Residuals: 26 BIC: 59.64
Df Model: 3
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 9.645e-16 0.102 9.44e-15 1.000 -0.210 0.210
Income 0.3140 0.111 2.824 0.009 0.085 0.543
Price -0.1324 0.106 -1.252 0.222 -0.350 0.085
Temperature 0.8633 0.111 7.762 0.000 0.635 1.092
==============================================================================
Omnibus: 0.565 Durbin-Watson: 1.021
Prob(Omnibus): 0.754 Jarque-Bera (JB): 0.047
Skew: 0.038 Prob(JB): 0.977
Kurtosis: 3.179 Cond. No. 1.47
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
En base al estadístico F y su p-value, se rechaza la hipótesis \(H_0\) de que todos los parámetros (slopes) son zeros (nulos), y podemos seguir examinando este modelo.
16.4.4.1. Utiliza R#
También podemos entrenar el modelo con R con la librereía lm.
df_r <- read.csv('data/ice_cream.csv', sep=",", strip.white=TRUE, header=TRUE)
head(df_r)
| Consumption | Income | Price | Temperature | |
|---|---|---|---|---|
| <dbl> | <int> | <dbl> | <int> | |
| 1 | 0.386 | 78 | 0.270 | 41 |
| 2 | 0.374 | 79 | 0.282 | 56 |
| 3 | 0.393 | 81 | 0.277 | 63 |
| 4 | 0.425 | 80 | 0.280 | 68 |
| 5 | 0.406 | 76 | 0.272 | 69 |
| 6 | 0.344 | 78 | 0.262 | 65 |
df_r_st <- as.data.frame(scale(df_r))
summary(df_r_st)
Consumption Income Price Temperature
Min. :-1.5722 Min. :-1.3770 Min. :-1.8340 Min. :-1.52845
1st Qu.:-0.7324 1st Qu.:-0.8566 1st Qu.:-0.8151 1st Qu.:-1.02607
Median :-0.1206 Median :-0.1761 Median : 0.2038 Median : 0.02436
Mean : 0.0000 Mean : 0.0000 Mean : 0.0000 Mean : 0.00000
3rd Qu.: 0.4836 3rd Qu.: 0.7445 3rd Qu.: 0.7432 3rd Qu.: 0.89210
Max. : 2.8662 Max. : 1.8253 Max. : 2.0018 Max. : 1.39448
R añade la intersección \(b_0\) automáticamente:
model_r <- lm(Consumption ~ Income + Price + Temperature, data=df_r_st)
summary(model_r)
Call:
lm(formula = Consumption ~ Income + Price + Temperature, data = df_r_st)
Residuals:
Min 1Q Median 3Q Max
-0.9926 -0.1805 0.0416 0.2425 1.2006
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.022e-16 1.022e-01 0.000 1.00000
Income 3.140e-01 1.112e-01 2.824 0.00899 **
Price -1.324e-01 1.058e-01 -1.252 0.22180
Temperature 8.633e-01 1.112e-01 7.762 3.1e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5598 on 26 degrees of freedom
Multiple R-squared: 0.719, Adjusted R-squared: 0.6866
F-statistic: 22.17 on 3 and 26 DF, p-value: 2.451e-07
Aquí, en R, obtenemos el mismo F-statistic y el mismo p-value.
16.4.5. Examina los residuos (diagnóstico residual)#
Necesitamos generar las respuestas predichas para examinar los residuos. Para predecir utilizamos el método predict de Python.
hatY = model.predict()
resid = model.resid
Gráfica de dispersión entre \(e_{i}\) y \(\hat y_i\)
Show code cell source
plot = hv.Scatter((hatY, resid), 'Predicted', 'Residuals').opts(width=330) * hv.HLine(0)
show(hv.render(plot))
Normalidad
Aquí sólo hacemos el Shapiro-Wilk test. Para un proceso completo, recomendamos los siguientes:
Histograma/densidad plot
Q-Q plot (tienes que dibujar la línea estandardizada; además, es mejor estandarizar los residuos primero)
Shapiro-Wilk test (mejor que muchos otros tests cuando \(N < 50\), pero también functiona para \(N \ge 50\))
Hay controversia sobre Kolmogorov–Smirnov (KS) test:
Algunos investigadores dijieron que KS test es mejor para \(N \ge 50\). Pero una limitación es que KS test requiere que la distribución teórica esté completamente especificada. Así que cuando utilizamos KS test y no sabemos la esperanza y varianza del normal, tenemos que utilizar una variante, Lilliefors test, o Anderson-Darling test.
Algunos investigadores dijieron que KS test tiene poca potencia y no debería considerarse seriamente para probar la normalidad. Además, no se recomienda cuando los parámetros se estiman a partir de los datos, independientemente del tamaño de la muestra. (Fuente)
Algunos investigadores recomiendan Shapiro-Wilk test como la mejor opción para comprobar la normalidad de los datos (fuente).
Ojo: hay variantes del procedimento para comprobar normalidad depende de cada investigador(a), e.g., sknewness test, kurtosis test.
Al final, hay que interpretar los resultados en tu tarea.
scipy.stats.shapiro(resid)
ShapiroResult(statistic=0.9443950653076172, pvalue=0.11948227882385254)
[Opcional] Gráfica de dispersión entre \(e_{i}\) y cada \(x_{.k}\)
Este paso es opcional, pero es útil para identificar predictores “problemáticos” (e.g., necesitan transformaciones).
Podemos visualizar el residuo en función de las variables independientes (usamos sus valores originales aquí).
Show code cell source
p = []
for var_name in ["Income", "Price", "Temperature"]:
p.append(hv.Scatter((df_st[var_name].values, resid), var_name+'_z', 'Residuals').opts(width=330) * hv.HLine(0))
plot = hv.Layout(p).cols(3).opts(hv.opts.Scatter(width=280, height=250))
show(hv.render(plot))
Los supuestos de residuos se cumplen.
16.4.6. Examina VIF#
Según nuestra pregunta 2, tenemos que examinar VIF. La calculación de VIF requiere un constante.
#Fuente: https://towardsdatascience.com/targeting-multicollinearity-with-python-3bd3b4088d0b
X = df_st[["Income", "Price", "Temperature"]]
X = sm.add_constant(X) #Añadimos el constante (intersección)
vif = pd.DataFrame()
vif["Variable"] = X.columns
vif["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif = vif[vif['Variable']!='intercept']
vif = vif[vif['Variable']!='const']
display(vif)
| Variable | VIF | |
|---|---|---|
| 1 | Income | 1.144186 |
| 2 | Price | 1.035673 |
| 3 | Temperature | 1.144367 |
En R, el cáculo de VIF es más fácil con la librería car:
library(car)
vif(model_r)
- Income
- 1.1441856587546
- Price
- 1.03567341852846
- Temperature
- 1.1443672320585
VIFs < 5, no tenemos el problema de multicolinealidad.
Importante
Sólo podemos confiar en los tests o usar el modelo (los coeficientes) para responder a nuestras preguntas de investigación (en los pasos siguientes) si los supuestos eran correctos.
16.4.7. Examina model fitness#
Para nuestras preguntas, necesitamos un modelo con buena calidad. ¿Cómo podemos medir la calidad del modelo ajustado de forma cuantitativa? (model fitness)
Podemos empezar mirando la gráfica de dispersión entre \(Y\) y \(\hat Y\):
Y = df_st["Consumption"]
plot = hv.Scatter((Y, hatY), 'Real', 'Predicted').opts(width=330) * hv.Slope(slope=1, y_intercept=0)
show(hv.render(plot))
El valor predicho sigue el valor real bastante bien.
Formalmente, tenemos que utilizar las métricas de fitness. Podemos verlos en el atributo summary de la estructura retornada:
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Consumption R-squared: 0.719
Model: OLS Adj. R-squared: 0.687
Method: Least Squares F-statistic: 22.17
Date: Sat, 10 Aug 2024 Prob (F-statistic): 2.45e-07
Time: 20:44:02 Log-Likelihood: -23.019
No. Observations: 30 AIC: 54.04
Df Residuals: 26 BIC: 59.64
Df Model: 3
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 9.645e-16 0.102 9.44e-15 1.000 -0.210 0.210
Income 0.3140 0.111 2.824 0.009 0.085 0.543
Price -0.1324 0.106 -1.252 0.222 -0.350 0.085
Temperature 0.8633 0.111 7.762 0.000 0.635 1.092
==============================================================================
Omnibus: 0.565 Durbin-Watson: 1.021
Prob(Omnibus): 0.754 Jarque-Bera (JB): 0.047
Skew: 0.038 Prob(JB): 0.977
Kurtosis: 3.179 Cond. No. 1.47
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Nos centramos en \(R^2\). ¿Qué significa el valor de \(R^2\)? ¿Es aceptable el valor?
16.4.8. Examina coeficientes#
Ahora podemos examinar los coeficientes. ¿Qué tan significativa es la contribución de cada predictor a la predicción controlando otros predictores?
Basándonos en los p-values de t-tests de los coeficientes, se rechanza \(H_0\) que los coeficientes asociados a la temperatura e ingreso sean cero (i.e., sus coeficientes no son cero). No hay evidencia suficiente para rechazar \(H_0\) para los coeficientes del precio y la intersección (i.e., sus coeficientes son cero).
Advertencia: la intersección es cero aquí porque hemos hacer la estandarización de la respuesta.
Puedes responder a las preguntas P1 y P2 (como la primera ronda)?
16.4.9. Refinamiento y seleción del modelos#
Usando los p-values de t-tests arriba, podemos eliminar “price”:
model_red = smf.ols('Consumption~Income+Temperature', data=df_st).fit()
print(model_red.summary())
OLS Regression Results
==============================================================================
Dep. Variable: Consumption R-squared: 0.702
Model: OLS Adj. R-squared: 0.680
Method: Least Squares F-statistic: 31.81
Date: Sat, 10 Aug 2024 Prob (F-statistic): 7.96e-08
Time: 20:16:32 Log-Likelihood: -23.897
No. Observations: 30 AIC: 53.79
Df Residuals: 27 BIC: 58.00
Df Model: 2
Covariance Type: nonrobust
===============================================================================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------------------------------------
Intercept 9.506e-16 0.103 9.2e-15 1.000 -0.212 0.212
Income 0.3351 0.111 3.017 0.006 0.107 0.563
Temperature 0.8844 0.111 7.963 0.000 0.657 1.112
==============================================================================
Omnibus: 2.264 Durbin-Watson: 1.003
Prob(Omnibus): 0.322 Jarque-Bera (JB): 1.094
Skew: 0.386 Prob(JB): 0.579
Kurtosis: 3.528 Cond. No. 1.40
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Observaciones: \(R^2\), \(R_{adj}^2\), \(F\)-statistic cambiaron un poco pero la significancia de F-test no cambió. Los valores de coeficientes permanecieron casi iguales y sus significancias no cambiaron.
Los residuos (y VIF): Se puede examinar los residuos (y VIF) de nuevo, aunque en este caso no es necesario porque hemos elinimado un predictor insignificativo de un modelo que ya cumple los supuestos de residuos y requisito de VIF, y no observamos cambios grandes especialmente con respecto a significancias estadísticas, así que no debería haber afectado al diagnóstico residual (y VIF).
Pero si tu nuevo modelo trae cambios grandes, tienes que examinar los residuos (y VIF) de nuevo. La examinación de VIF se pone entre paréntesis porque depende de tu pregunta de investigación.
Cómo selecionar el mejor modelo?
\(R^2\) adjustado (\(R^2_{adj}\))
Los \(R^2\) (“R-squared”) no son muy confiables en seleción de modelos, porque cada vez que agregas una variable, el \(R^2\) aumenta o queda igual! Además, algunas de las variables independientes (predictores) pueden volverse significativas.
Usamos \(R^2\) adjustado (“Adj. R-squared”) en su lugar. \(R^2\) ajustado es una variación de \(R^2\) que proporciona un ajuste para el número de parámetros (o el grado de libertad):
Advertencia
A diferencia del \(R^2\), el \(R^2\) ajustado no está acotado entre 0 y 1 y no debe interpretarse de manera similar a la medida del \(R^2\) (no refleja qué porcentaje de error se está explicando).
El modelo completo tiene el mejor \(R_{adj}^2\) (.687) que el modelo reducido aquí (.680). Si tenemos que selecionar un modelo y usamos \(R_{adj}^2\) para elegir, podemos selecionar el modelo completo.
F-test lineal general
Sin embargo, muchas investigadores preferen un modelo más pequeño, dado que no hay diferencia estadística entre los models. En este caso, hacemos un F-test lineal general presentado anteriormente. Si rechazamos \(H_0\) (con \(p\)<.05), rechazamos el modelo reducido en favor de el modelo completo (o más grande).
Aquí, utilizamos statsmodels.stats.anova.anova_lm para hacer una comparación con F-test lineal general:
anovaResults = anova_lm(model_red, model)
display(anovaResults)
| df_resid | ssr | df_diff | ss_diff | F | Pr(>F) | |
|---|---|---|---|---|---|---|
| 0 | 27.0 | 8.640292 | 0.0 | NaN | NaN | NaN |
| 1 | 26.0 | 8.149178 | 1.0 | 0.491113 | 1.5669 | 0.221803 |
Aquí, \(p\)=.22>.05, no hay diferencia significativa entre los modelos. Eligimos el modelo reducido (sin precio).
También podemos selectionar el modelo según AIC, BIC, cross-validation, etc.
Diferentes investigadores (dependen de las preguntas de investigaciones) pueden tener preferencias diferentes.
16.4.10. Resumen & conclusión#
Resumen
Empezamos con una regresión lineal múlitple que predice el consumo de helados por ingreso, precio y temperature (M1). Esto resultó en un modelo general significativo, \(F\)(3, 26)=22.17, \(p\)<.001, \(R^2\)=.719, \(R_{adj}^2\)=.687. Los residuos y VIF fueron examinados y cumplieron los supuestos y requisitos. Los predictores individuales fueron examinados luego y señalaron que el ingreso (\(\beta\)=0.31, \(p\)=.009) y temperature (\(\beta\)=0.86, \(p\)<.001) fueron predictores significativos, pero el precio no fue un predictor significativo (\(\beta\)=-0.13, \(p\)=.22).
Construimos otra regresión lineal múlitple que predice el consumo de helados por ingreso y temperature, sin precio (M2). Esto resultó en un modelo general significativo, \(F\)(2, 27)=31.81, \(p\)<.001, \(R^2\)=.702, \(R_{adj}^2\)=.680. Aunque el modelo completo (M1) tiene el mejor \(R_{adj}^2\) que el modelo reducido (M2), no hay diferencia significativa entre dos modelos (\(p\)=.22). Preferimos un modelo más pequeño, así que eligimo el modelo reducido (M2).
Conclusión
Ahora, revisamos las preguntas (de nuevo) y sacamos conclusiones.
P1: ¿Existe una relación lineal entre el consumo de helados y la combinación del ingreso, la temperatura y el precio? (O podemos explicar el consumo de helados por el ingreso, la temperatura y el precio juntos?)
Si, pero la contribución del precio no es significativa estadísticalmente. Podemos explicar el consumo de helados por el ingreso y la temperatura juntos suficientemente. Más específicamente, cuando el ingreso y la temperatura sean más altos, el consumo de helados se vuelve más alto.
P2: ¿Qué variable es más importante para explicar el consumo de helados?
La temperatura es más importante para explicar el consumo de helados, según su coeficiente (\(\beta\)=0.88) en un modelo con predictores ingreso y temperatura. Cuando la temperatura augmenta una desviación estándar (SD) controlando por ingreso, el consumo de helados augmenta 0.88SD pintas per capita, en promedio.
Truco
Una convención: usamos \(b\) cuando los coeficientes no están estándarizados, y usamos \(\beta\) cuando los coeficientes están estándarizados.
16.5. Notas finales del pipeline básico#
Terminamos el pipeline básico, pero tu viaje comienza aquí :)
Si sólo te interesa el rendimiento de la predicción y no te importa si el modelo tiene sentido, no te importa el valor o la significancia de los coeficientes, a menudo basta con comprobar algunas métricas de adecuación (fitness) o predictividad (predictiveness), e.g., \(R^2\), \(R_{adj}^2\), AIC, BIC, RMSE, AUC, sin comprobar la violación de los supuestos, la multicolinealidad, etc. Pero en este curso queremos que utilices el pipieline completa :)
Si tienes preguntas más abiertas, el pipeline se vuelve más complejo. Por ejemplo, para la pregunta
¿Cúal es el mejor modelo de regresión para explicar el consumo de helados?
podemos aplicar un procesos para la seleción de modeo: selección de avance (forward selection), eliminación hacia atrás (backward elimination) o ambos. Esta pagina los explica claramente (puedes usar otras métricas como AIC, BIC no mencionadas en la pagina). Además, podemos considerar stepwise regresión para buscar un mejor modelo automáticamente (con precaución).
Hay que tener precaución en estos procesos:
Tenemos que considerar teoría relevante sobre las variables. Con mucha frecuencia preferimos un modelo teóricamente sólido y razonable que un modelo más predictivo.
Si el valor o la significancia de los coeficientes nos importan (e.g., para explicar/entender un fenómeno), tenemos que examinar VIF y evitar multicolinealidad también.
Además de los modelos mencionados brevemente en “Supuestos y requisitos para regresión lineal”, hay otros tópicos muy utiles sobre regresión lineal:
Regresión con variables categóricas
Regresión con interacción
Modelo de efectos mixtos
Regresicón polinómica
Más adelante, veamos regresión lineal con funciones base y regularización y regresiones para respuestas discretas!
Ahora, veamos algunos tópicos específicos (1, 2), y usaremos R!
16.6. Variables categóricas (opcional)#
¿Qué pasa si tenemos variables categóricas? Veamos el Movie dataset de Kaggle! Este dataset se compone de 651 películas de muestra aleatoria producidas y entrenadas antes de 2016.
Siempre empezamos por examinar tipos de variables, las estadísticas descriptivas, el análisis exploratorio de datos.
library(vtable)
library(dplyr)
load("data/movies.RData")
df <- movies[c("imdb_rating", "genre")]
str(df)
head(df, 5)
vtable::st(df, add.median=TRUE, out='kable', digits=3)
tibble [651 x 2] (S3: tbl_df/tbl/data.frame)
$ imdb_rating: num [1:651] 5.5 7.3 7.6 7.2 5.1 7.8 7.2 5.5 7.5 6.6 ...
$ genre : Factor w/ 11 levels "Action & Adventure",..: 6 6 4 6 7 5 6 6 5 6 ...
| imdb_rating | genre |
|---|---|
| <dbl> | <fct> |
| 5.5 | Drama |
| 7.3 | Drama |
| 7.6 | Comedy |
| 7.2 | Drama |
| 5.1 | Horror |
Table: Summary Statistics
|Variable |N |Mean |Std. Dev. |Min |Pctl. 25 |Pctl. 50 |Pctl. 75 |Max |
|:-----------------------------|:---|:-----|:---------|:---|:--------|:--------|:--------|:---|
|imdb_rating |651 |6.49 |1.08 |1.9 |5.9 |6.6 |7.3 |9 |
|genre |651 | | | | | | | |
|... Action & Adventure |65 |10% | | | | | | |
|... Animation |9 |1.4% | | | | | | |
|... Art House & International |14 |2.2% | | | | | | |
|... Comedy |87 |13.4% | | | | | | |
|... Documentary |52 |8% | | | | | | |
|... Drama |305 |46.9% | | | | | | |
|... Horror |23 |3.5% | | | | | | |
|... Musical & Performing Arts |12 |1.8% | | | | | | |
|... Mystery & Suspense |59 |9.1% | | | | | | |
|... Other |16 |2.5% | | | | | | |
|... Science Fiction & Fantasy |9 |1.4% | | | | | | |
# Variable dependiente (DV)
options(repr.plot.width=3, repr.plot.height=3)
hist(df$imdb_rating)
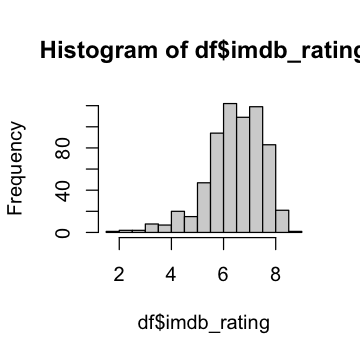
# Predictor
df %>% group_by(genre) %>%
summarise(n_rows=length(genre),
M_rating=mean(imdb_rating), #media
Mdn_rating=median(imdb_rating),#mediana
SD_rating=sd(imdb_rating)
)
| genre | n_rows | M_rating | Mdn_rating | SD_rating |
|---|---|---|---|---|
| <fct> | <int> | <dbl> | <dbl> | <dbl> |
| Action & Adventure | 65 | 5.970769 | 6.00 | 1.2065865 |
| Animation | 9 | 5.900000 | 6.40 | 1.4924812 |
| Art House & International | 14 | 6.614286 | 6.50 | 0.9180725 |
| Comedy | 87 | 5.744828 | 5.70 | 1.1797476 |
| Documentary | 52 | 7.648077 | 7.60 | 0.4103993 |
| Drama | 305 | 6.673443 | 6.80 | 0.8798454 |
| Horror | 23 | 5.760870 | 5.90 | 0.8742473 |
| Musical & Performing Arts | 12 | 7.300000 | 7.55 | 0.6741999 |
| Mystery & Suspense | 59 | 6.479661 | 6.50 | 0.8262461 |
| Other | 16 | 6.631250 | 6.80 | 1.1388408 |
| Science Fiction & Fantasy | 9 | 5.755556 | 5.90 | 1.7299647 |
16.6.1. Tratarlo como numérico#
df$genre_num <- as.numeric(df$genre)
summary(lm(imdb_rating ~ genre_num, data=df))
Call:
lm(formula = imdb_rating ~ genre_num, data = df)
Residuals:
Min 1Q Median 3Q Max
-4.4826 -0.5971 0.1320 0.7744 2.2598
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.09651 0.11270 54.094 < 2e-16 ***
genre_num 0.07152 0.01885 3.793 0.000163 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.074 on 649 degrees of freedom
Multiple R-squared: 0.02169, Adjusted R-squared: 0.02018
F-statistic: 14.39 on 1 and 649 DF, p-value: 0.0001626
16.6.2. Tratarlo como tipo factor con variables dummy#
str(df$genre)
levels(df$genre)
Factor w/ 11 levels "Action & Adventure",..: 6 6 4 6 7 5 6 6 5 6 ...
- 'Action & Adventure'
- 'Animation'
- 'Art House & International'
- 'Comedy'
- 'Documentary'
- 'Drama'
- 'Horror'
- 'Musical & Performing Arts'
- 'Mystery & Suspense'
- 'Other'
- 'Science Fiction & Fantasy'
Aquí, un variable de tipo factor en R es un conjunto de variables “dummy”. Una variable dummy es una variable binaria (1 o 0) para representar el efecto de una variable categórica. Para una variable categórica con \(n\) niveles, utilizamos \(n-1\) variables dummy. Por ejemplo, para una variable categórica SES (social economic status), creamos dos variables dummy, y el nivel que tiene 0s en todas las variables dummy es el grupo de referencia.
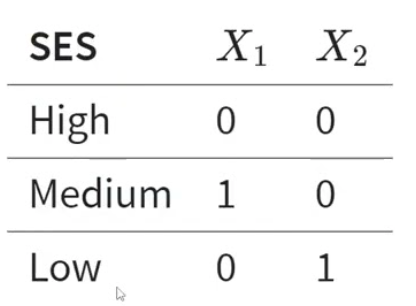 (Fuente)
(Fuente)
¿Por qué utilizamos \(n-1\) en lugar de \(n\) variables dummy?
¿Cuántas variables dummy tenemos en el movie dataset?
model <- lm(imdb_rating ~ genre, data=df)
summary(model)
Call:
lm(formula = imdb_rating ~ genre, data = df)
Residuals:
Min 1Q Median 3Q Max
-3.9734 -0.4734 0.0552 0.6234 2.5203
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.97077 0.11913 50.120 < 2e-16 ***
genreAnimation -0.07077 0.34160 -0.207 0.83594
genreArt House & International 0.64352 0.28299 2.274 0.02330 *
genreComedy -0.22594 0.15746 -1.435 0.15181
genreDocumentary 1.67731 0.17869 9.386 < 2e-16 ***
genreDrama 0.70267 0.13121 5.355 1.19e-07 ***
genreHorror -0.20990 0.23302 -0.901 0.36805
genreMusical & Performing Arts 1.32923 0.30177 4.405 1.24e-05 ***
genreMystery & Suspense 0.50889 0.17270 2.947 0.00333 **
genreOther 0.66048 0.26804 2.464 0.01400 *
genreScience Fiction & Fantasy -0.21521 0.34160 -0.630 0.52890
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9605 on 640 degrees of freedom
Multiple R-squared: 0.2281, Adjusted R-squared: 0.216
F-statistic: 18.91 on 10 and 640 DF, p-value: < 2.2e-16
¿Qué significa el coeficiente 5.97 del Intercept? ¿Qué significa el coeficiente -0.07 del genreAnimation?
Nota
No se cumple la normalidad de residual (véase más abajo). El modelo debe modificarse. Por ahora, nos detenemos aquí sólo para aprender a procesar variables categóricas.
options(repr.plot.width=3, repr.plot.height=3)
res <- resid(model)
plot(density(res))
qqnorm(res)
qqline(res)
ks.test(res, "pnorm")

Asymptotic one-sample Kolmogorov-Smirnov test
data: res
D = 0.36966, p-value < 2.2e-16
alternative hypothesis: two-sided
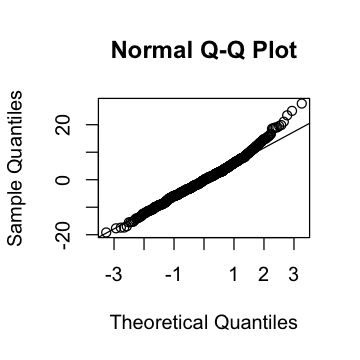
16.6.3. Tratarlo como tipo factor con nivel básico específico#
Si nos interesan los índices (ratings) de otros tipos de películas en comparación con el Drama, ¿qué hacemos?
levels(df$genre)
- 'Action & Adventure'
- 'Animation'
- 'Art House & International'
- 'Comedy'
- 'Documentary'
- 'Drama'
- 'Horror'
- 'Musical & Performing Arts'
- 'Mystery & Suspense'
- 'Other'
- 'Science Fiction & Fantasy'
new_levels <- c(c("Drama"), levels(df$genre)[-6])
df$genre.drama <- factor(df$genre, levels=new_levels)
levels(df$genre.drama)
- 'Drama'
- 'Action & Adventure'
- 'Animation'
- 'Art House & International'
- 'Comedy'
- 'Documentary'
- 'Horror'
- 'Musical & Performing Arts'
- 'Mystery & Suspense'
- 'Other'
- 'Science Fiction & Fantasy'
summary(lm(imdb_rating ~ genre.drama, data=df))
Call:
lm(formula = imdb_rating ~ genre.drama, data = df)
Residuals:
Min 1Q Median 3Q Max
-3.9734 -0.4734 0.0552 0.6234 2.5203
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.67344 0.05500 121.346 < 2e-16 ***
genre.dramaAction & Adventure -0.70267 0.13121 -5.355 1.19e-07 ***
genre.dramaAnimation -0.77344 0.32484 -2.381 0.01756 *
genre.dramaArt House & International -0.05916 0.26252 -0.225 0.82178
genre.dramaComedy -0.92862 0.11674 -7.955 8.16e-15 ***
genre.dramaDocumentary 0.97463 0.14410 6.764 3.04e-11 ***
genre.dramaHorror -0.91257 0.20768 -4.394 1.30e-05 ***
genre.dramaMusical & Performing Arts 0.62656 0.28266 2.217 0.02700 *
genre.dramaMystery & Suspense -0.19378 0.13660 -1.419 0.15650
genre.dramaOther -0.04219 0.24633 -0.171 0.86405
genre.dramaScience Fiction & Fantasy -0.91789 0.32484 -2.826 0.00487 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9605 on 640 degrees of freedom
Multiple R-squared: 0.2281, Adjusted R-squared: 0.216
F-statistic: 18.91 on 10 and 640 DF, p-value: < 2.2e-16
16.7. Interacción (opcional)#
A veces, el efecto de un predictor depende en otro(s) predictor(es). En este caso, utilizamos interacciones en la regresión lineal, donde construimos términos de interacción multiplicando predictores (e.g., predictor1 x predictor2)[1]. Un término de interacción puede tener muchos predictores (e.g., predictor1 x predictor2 x predictor3 …). En esta lección, sólo consideramos “two-way interaction” (i.e., con dos predictores), y hay 3 casos en los que varián sus tipos de variable:
Categórica x Categórica
Categórica x Continua
Continua x Continua
En esta lección, sólo analizamos el primer caso.
[1] En sentido estricto, multiplicamos las variables dummy de los predictores.
Veamos un ejemplo de un estudio hipotético sobre pérdida de peso. En este estudio, 900 personas participaron en un estudio de un año sobre el efecto de 3 programas en la pérdida de peso: jogging, natación, lectura. El program de lectura es el grupo de control.
library(vtable)
library(dplyr)
library(emmeans)
library(ggplot2)
df <- read.csv("https://stats.idre.ucla.edu/wp-content/uploads/2019/03/exercise.csv")
str(df)
vtable::st(df, add.median=TRUE, out='kable', digits=3)
'data.frame': 900 obs. of 6 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ loss : num 18.02 10.19 19.75 1.88 14.24 ...
$ hours : num 1.84 2.39 2.36 2.52 1.89 ...
$ effort: num 37.7 26.7 36.3 20.7 24.7 ...
$ gender: int 1 1 1 1 1 1 1 1 1 1 ...
$ prog : int 1 1 1 1 1 1 1 1 1 1 ...
Table: Summary Statistics
|Variable |N |Mean |Std. Dev. |Min |Pctl. 25 |Pctl. 50 |Pctl. 75 |Max |
|:--------|:---|:----|:---------|:-----|:--------|:--------|:--------|:----|
|id |900 |450 |260 |1 |226 |450 |675 |900 |
|loss |900 |10 |14.1 |-17.1 |-1.74 |7.88 |20 |54.2 |
|hours |900 |2 |0.495 |0.175 |1.68 |2.01 |2.34 |4.07 |
|effort |900 |29.7 |5.14 |12.9 |26.3 |29.6 |33.1 |44.1 |
|gender |900 |1.5 |0.5 |1 |1 |1.5 |2 |2 |
|prog |900 |2 |0.817 |1 |1 |2 |3 |3 |
loss: la pérdida de peso (continua): positivo = pérdida de peso, negativo = aumento de pesohours: horas dedicadas al ejercicio (continua)effort: esfuerzo durante el ejercicio (continua): 0 = esfuerzo físico mínimo, 50 = esfuerzo máximoprog: programa de ejercicio (categórica): 1 = jogging (jogging), 2 = swimming (natación), 3 = reading (lectura)gender: género del participante (categórica y binaria): 1 = male (hombre), 2 = female (mujer)
Aquí, las variables prog y gender son categóticas conceptualmente, pero los datos cargados en R no son de tipo factor. Tenemos que convertirlas en este tipo y especificar el grupo (nivel) de referencia. (También cambiamos el nombre de la variable loss.)
df$prog <- factor(df$prog, levels=c(1, 2, 3), labels=c("jog", "swim", "read"))
df$gender <- factor(df$gender, levels=c(1, 2), labels=c("male", "female"))
levels(df$prog)
levels(df$gender)
df$prog <- relevel(df$prog, ref="read")
df$gender <- relevel(df$gender, ref="female")
levels(df$prog)
levels(df$gender)
- 'jog'
- 'swim'
- 'read'
- 'male'
- 'female'
- 'read'
- 'jog'
- 'swim'
- 'female'
- 'male'
Siempre empezamos examinando primero los modelo sin interacción, y empezamos por examinar las estadísticas descriptivas.
df %>% group_by(prog) %>%
summarise(n_rows=length(loss),
M_loss=mean(loss),
SD_loss=sd(loss))
df %>% group_by(gender) %>%
summarise(n_rows=length(loss),
M_loss=mean(loss),
SD_loss=sd(loss))
| prog | n_rows | M_loss | SD_loss |
|---|---|---|---|
| <fct> | <int> | <dbl> | <dbl> |
| read | 300 | -3.787878 | 4.114563 |
| jog | 300 | 8.030355 | 7.452667 |
| swim | 300 | 25.820037 | 8.919916 |
| gender | n_rows | M_loss | SD_loss |
|---|---|---|---|
| <fct> | <int> | <dbl> | <dbl> |
| female | 450 | 9.928741 | 15.41056 |
| male | 450 | 10.112935 | 12.67177 |
summary(lm(loss~prog, data=df))
Call:
lm(formula = loss ~ prog, data = df)
Residuals:
Min 1Q Median 3Q Max
-22.4700 -4.6636 -0.0762 4.1810 28.3304
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.7879 0.4110 -9.216 <2e-16 ***
progjog 11.8182 0.5813 20.332 <2e-16 ***
progswim 29.6079 0.5813 50.938 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.119 on 897 degrees of freedom
Multiple R-squared: 0.7457, Adjusted R-squared: 0.7451
F-statistic: 1315 on 2 and 897 DF, p-value: < 2.2e-16
summary(lm(loss~gender, data=df))
Call:
lm(formula = loss ~ gender, data = df)
Residuals:
Min 1Q Median 3Q Max
-27.067 -11.788 -2.156 9.977 44.222
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 9.9287 0.6650 14.929 <2e-16 ***
gendermale 0.1842 0.9405 0.196 0.845
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 14.11 on 898 degrees of freedom
Multiple R-squared: 4.271e-05, Adjusted R-squared: -0.001071
F-statistic: 0.03835 on 1 and 898 DF, p-value: 0.8448
Ahora, veamos la estadísticas descriptivas relacionadas con la combinación de programa y género.
options(dplyr.summarise.inform = FALSE) #suppress group_by warning message
df %>% group_by(prog, gender) %>%
summarise(n_rows=length(loss),
M_loss=mean(loss), #media
Mdn_loss=median(loss),#mediana
SD_loss=sd(loss)
)
| prog | gender | n_rows | M_loss | Mdn_loss | SD_loss |
|---|---|---|---|---|---|
| <fct> | <fct> | <int> | <dbl> | <dbl> | <dbl> |
| read | female | 150 | -3.620149 | -3.205774 | 4.095709 |
| read | male | 150 | -3.955606 | -4.151879 | 4.140218 |
| jog | female | 150 | 4.288681 | 4.574300 | 6.885004 |
| jog | male | 150 | 11.772028 | 11.756875 | 5.988807 |
| swim | female | 150 | 29.117691 | 29.146642 | 7.996907 |
| swim | male | 150 | 22.522383 | 20.667851 | 8.591756 |
Parece el efecto del programa depende del género, aunque el género por sí mismo no tiene efecto.
Construimos un modelo con interacción entre program y género:
\(\hat{loss} = b_0 + b_1 D_{male} + b_2 D_{jog} + b_3 D_{swim} + b_4 D_{male} * D_{jog} + b_5 D_{male} * D_{swim}\)
model <- lm(loss~gender*prog,data=df)
summary(model)
Call:
lm(formula = loss ~ gender * prog, data = df)
Residuals:
Min 1Q Median 3Q Max
-19.1723 -4.1894 -0.0994 3.7506 27.6939
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.6201 0.5322 -6.802 1.89e-11 ***
gendermale -0.3355 0.7527 -0.446 0.656
progjog 7.9088 0.7527 10.507 < 2e-16 ***
progswim 32.7378 0.7527 43.494 < 2e-16 ***
gendermale:progjog 7.8188 1.0645 7.345 4.63e-13 ***
gendermale:progswim -6.2599 1.0645 -5.881 5.77e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 6.519 on 894 degrees of freedom
Multiple R-squared: 0.7875, Adjusted R-squared: 0.7863
F-statistic: 662.5 on 5 and 894 DF, p-value: < 2.2e-16
¿Qué significa el coeficiente -0.3355 de gendermale?
¿Qué significa el coeficiente -6.2599 de gendermale:progswim?
¡Dibujemoss el gráfico de interración para entenderlo mejor!
options(repr.plot.width=3, repr.plot.height=3)
obj <- emmeans::emmip(model, prog ~ gender, CIs=TRUE, plotit=FALSE)
obj
ggplot(data=obj, aes(x=gender, y=yvar, color=prog, group=prog)) + geom_line() + geom_point() +
geom_errorbar(aes(ymax=UCL, ymin=LCL, width=0.2)) +
labs(x="Gender", y="Weight Loss", color="Program") +
theme(text = element_text(size=16))
| prog | gender | yvar | SE | df | LCL | UCL | tvar | xvar | |
|---|---|---|---|---|---|---|---|---|---|
| <fct> | <fct> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <fct> | <fct> | |
| 1 | read | female | -3.620149 | 0.5322428 | 894 | -4.664740 | -2.575559 | read | female |
| 2 | jog | female | 4.288681 | 0.5322428 | 894 | 3.244091 | 5.333272 | jog | female |
| 3 | swim | female | 29.117691 | 0.5322428 | 894 | 28.073100 | 30.162282 | swim | female |
| 4 | read | male | -3.955606 | 0.5322428 | 894 | -5.000197 | -2.911016 | read | male |
| 5 | jog | male | 11.772028 | 0.5322428 | 894 | 10.727437 | 12.816619 | jog | male |
| 6 | swim | male | 22.522383 | 0.5322428 | 894 | 21.477792 | 23.566974 | swim | male |
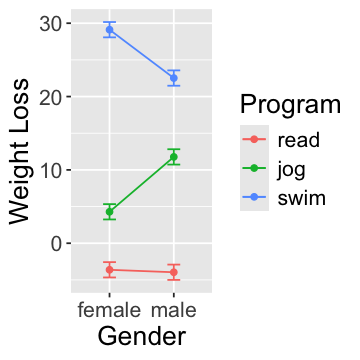
¿Cómo interpreta y describe esta interración?
Resumen
Un regresión que predice Weight Loss con los predictores Program, Gender, y Program \(\times\) Gender (\(F(5, 894)\)=662.5, \(p\)<.001) revela una interacción significativa entre Program y Gender (\(b_{male \times jog}\)=7.82, \(p\)<.001; \(b_{male \times swim}\)=-6.26, \(p\)<.001). Concretamente, mientras que en el programma de lectura (read), ambos géneros tuvieron el mismo nivel de pérdidad de peso, en el programa de jogging (jog), los hombres perdieron más peso que las mujerers, pero perdieron menos pesos que las mujerers en el programa de natación (swim).
Te animamos a estudiar los otros dos casos de interacción (con el mismo estudio hipotético sobre pérdida de peso):
Categórica x Continua
Continua x Continua