4. Variables Aleatorias Especiales#
Existen algunos tipos de variables aleatorias especiales, definidas por que tienen distribuciones de probabilidad particulares.
4.1. Distribución Bernoulli#
Suponga que se realiza un ensayo cuya salida es “éxito” o “falla”. La v.a. entonces tiene sólo dos valores posibles: 1 si “éxito” 0 si no. Si \(p\) es la probabilidad de éxito, entonces:
\(\begin{array}{lll} P(X=1) & = &p \\ P(X=0) & = & 1-p \\ P(X = x) & = & p^x (1-p)^{1-x} \,, x=0,1\\ E[X] & = & p\\ Var(X) & = & p(1-p)\\ Asimetria(X) & = & \frac{1-2p}{\sqrt{p(1-p)}} = \frac{q-p}{\sqrt{pq}} (q=1-p)\\ Curtosis(X) & = & \frac{1-3p+3p^2}{p(1-p)} = \frac{1-3pq}{pq} (q=1-p)\\ \end{array}\)
¿Cómo se dibuja su función de masa de probabilidad? ¿Se te ocurre algún ejemplo de esta distribución?
4.2. Distribución Binomial#
Suponga que se realizan \(n\) ensayos independientes idénticos Bernoulli de parámetro \(p\). La v.a. X que representa el número \(x\) de ensayos existosos entre los \(n\) ensayos realizados, se denomina Binomial y cumple:
\(\begin{array}{lll} P(X=x) & = & {n \choose x} p^x (1-p)^{n-x}, \qquad x=0,1,...n \\ E[X] & = & np\\ Var(X) & = & np(1-p)\\ Asimetria(X) & = & \frac{1-2p}{\sqrt{np(1-p)}} = \frac{q-p}{\sqrt{npq}} (q=1-p)\\ Curtosis(X) & = & \frac{1-3p(1-p)}{np(1-p)} = \frac{1-3pq}{npq} (q=1-p)\\ \end{array}\)
options(repr.plot.width=16, repr.plot.height=5)
par(mfrow=c(1,3))
par(cex=1.2)
vec <- seq(0,40,by=1)
pvec1 <- dbinom(vec,prob=0.2,size=40)
pvec2 <- dbinom(vec,prob=0.5,size=40)
pvec3 <- dbinom(vec,prob=0.8,size=40)
plot(vec,pvec1,type="h",col = "red", xlab = "k (# de exitos)", ylab = "Probabilidad", main = "Funcion Probabilidad Binomial (p=0.2)")
points(vec,pvec1,col="red")
plot(vec,pvec2,type="h",col = "black", xlab = "k (# de exitos)", ylab = "Probabilidad", main = "Funcion Probabilidad Binomial (p=0.5)")
points(vec,pvec2,col="black")
plot(vec,pvec3,type="h",col = "blue", xlab = "k (# de exitos)", ylab = "Probabilidad", main = "Funcion Probabilidad Binomial (p=0.8)")
points(vec,pvec3,col="blue")
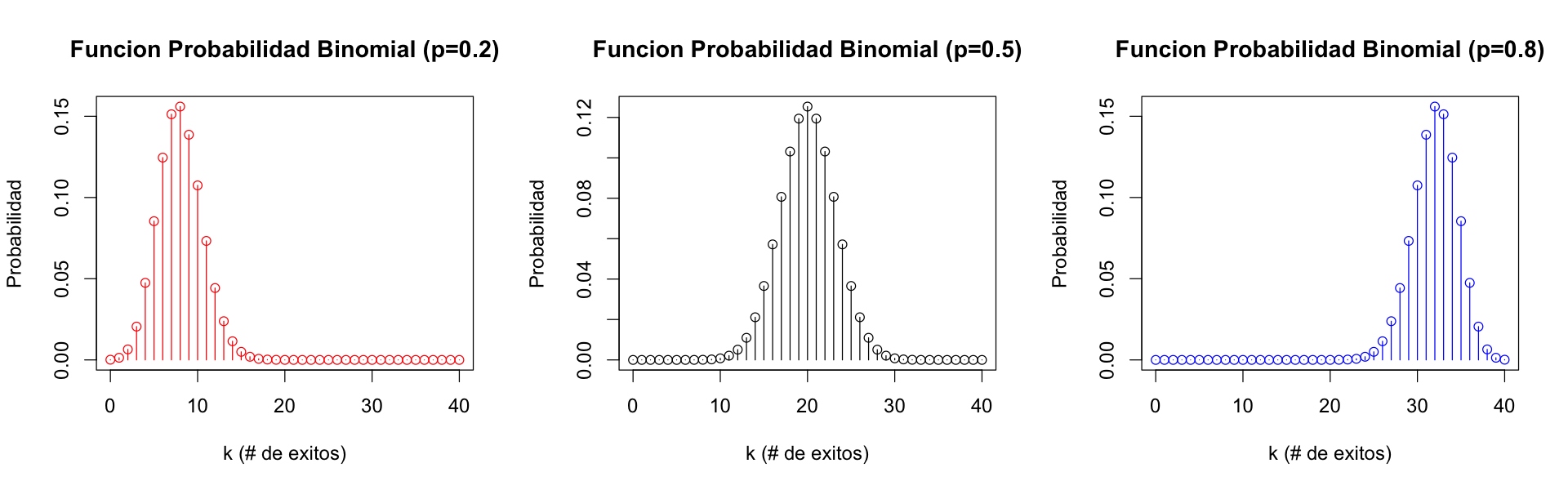
¿Se te ocurre algún ejemplo de esta distribución?
4.3. Distribución Exponencial#
Sea \(X\) v.a. continua, es exponencial de tasa \(\lambda\) si su densidad de probabilidad cumple:
\(\begin{array}{lll} f(x) & = & \lambda e^{-\lambda x},\qquad x \geq 0, \lambda > 0\\ F(x) & = & 1- e^{-\lambda x}\\ E[X] &= &\frac{1}{\lambda}\\ Var(X)& =& \frac{1}{\lambda^2}\\ Asimetria(X) & = & 2\\ Curtosis(X) & = & 9 \\ \end{array}\)
##distribución exponencial
options(repr.plot.width=5, repr.plot.height=5)
par(cex=1.2)
vec <- seq(0,5,by=0.05)
pvec1 <- dexp(vec,2)
pvec2 <- dexp(vec,1)
pvec3 <- dexp(vec,0.5)
## Si usamos las funciones incorporadas en R
plot(vec, pvec1, type="l", col="black", main="Densidad Exponencial", xlab="x", ylab="densidad de probabilidad")
lines(vec, pvec2, col="blue")
lines(vec, pvec3, col="red")
legend(x="topright", lty=1, legend=c("t=2", "t=1", "t=0.5"), col=c("black", "blue", "red"), text.width=0.8)
## Si usamos rbokeh
# library("rbokeh")
# p <- figure(plot_width=600,plot_height=200, title="Densidad Exponencial", title_location="above", legend_location = "top_right") %>%
# ly_lines(vec,pvec1,legend="l=2") %>%
# ly_lines(vec,pvec2,col="blue",legend="l=1") %>%
# ly_lines(vec,pvec3,col="red",legend="l=0.5")
# p
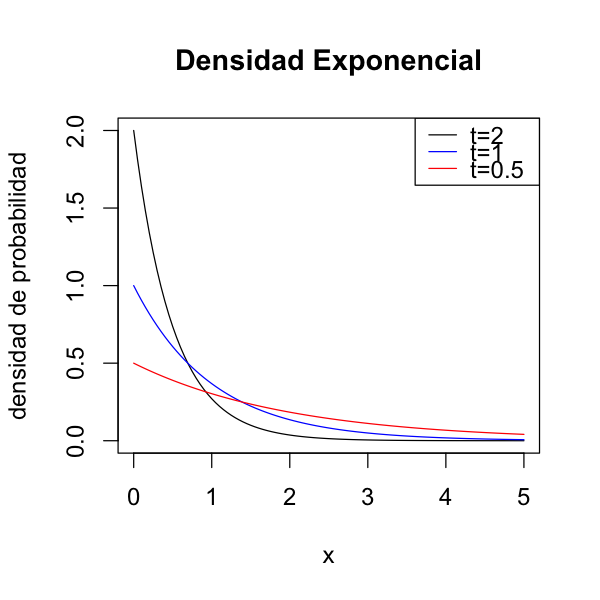
¿Crees que lo siguiente puede modelarse mediante una función exponencial?
La cantidad de dinero que la gente gasta en un viaje al supermercado (es decir, hay más personas que gastan pequeñas cantidades de dinero y menos personas que gastan grandes cantidades de dinero)
El valor del cambio que la gente tiene en su bolsillo o bolso
El tiempo que dura una batería de tu móvil
4.4. Distribución Normal o Gaussiana#
Sea \(X\) v.a. continua, es normal de media \(\mu\) y varianza \(\sigma^2\) y se denota \(\cal{N}(\mu,\sigma^2)\) si su densidad de probabilidad cumple:
\(\begin{array}{lll} f(x) & = & \frac{1}{\sigma\sqrt{2\pi}} exp(-\frac{(x-\mu)^2}{2\sigma^2}),\qquad x \in \mathbb{R}\\ E[X] &= &\mu\\ Var(X)& =& \sigma^2\\ Asimetria(X) & = & 0\\ Curtosis(X) & = & 3 \\ \end{array}\)
Esta es la distribución de probabilidad mas utilizada.
Muchas variables se distribuyen aproximadamente normales (altura, peso, satisfacción en el trabajo, etc.). También permite modelar los errores o ruidos.
La usamos en Teorema de límite central, tests de hipótesis paramétricos, inferencia estadística clásica.
¿Cómo se verifica que una v.a. sigue una distribución normal?
Test de normalidad de Shapiro-Wilk, K-S, Q-Q plot, asimetría y curtosis
##Distribución Gaussiana
options(repr.plot.width=4, repr.plot.height=4)
vec <- seq(-6, 6, by=0.05)
pvec1 <- dnorm(vec, 0, 0.4)
pvec2 <- dnorm(vec, 0, 1)
pvec3 <- dnorm(vec, 0, 3)
pvec4 <- dnorm(vec, -2, 0.6)
## Si usamos las funciones incorporadas en R
par(cex=1.2)
plot(vec, pvec1, type="l", col="blue", main="Densidad Gaussiana", xlab="x", ylab="densidad de probabilidad")
lines(vec, pvec2, col="black")
lines(vec, pvec3, col="red")
lines(vec, pvec4, col="green")
legend(x="topright", lty=1, legend=c("m=0,s=0.4", "m=0,s=1", "m=0,s=3", "m=-2,s=0.6"), col=c("blue", "black", "red", "green"), text.width=3.2)
## Si usamos rbokeh
# library("rbokeh")
# p <- figure(plot_width=600,plot_height=200, title="Densidad Gaussiana", title_location="above", legend_location = "top_right") %>%
# ly_lines(vec,pvec1,legend="m=0, s=0.4") %>%
# ly_lines(vec,pvec2,col="blue",legend="m=0, s=1") %>%
# ly_lines(vec,pvec3,col="red",legend="m=0, s=3") %>%
# ly_lines(vec,pvec4,col="green",legend="m=-2, s=0.6")
# p
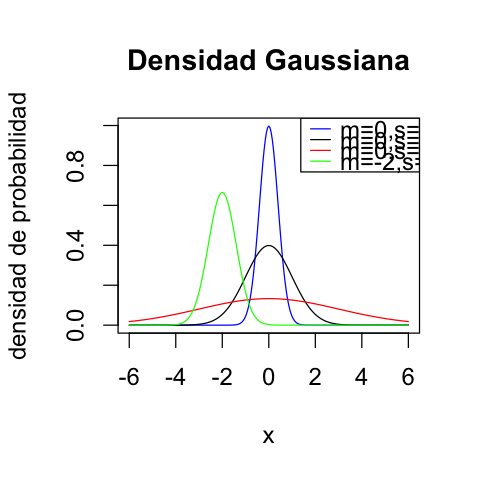
4.4.1. Distribución Normal Estándar (Estandarizada)#
\(Z \sim \cal{N}(0,1)\) si su densidad de probabilidad cumple:
\(\begin{array}{lll} f(x) & = & \frac{1}{\sqrt{2\pi}} exp(-\frac{x^2}{2}), \qquad x \in \mathbb{R}\\ E[X] &= &0\\ Var(X)& =&1\\ \end{array}\)
Usualmente, la densidad de probabilidad f(x) y la distribución acumulativa F(x) de Normal estándar se denominan \(\phi(z)\) y \(\Phi(z)\).
Si \(X \sim \cal{N}(\mu,\sigma^2)\), entonces \(Z = \frac{X-\mu}{\sigma} \sim \cal{N}(0,1)\)
Esta transformación se denomina “Z-score” y se utiliza incluso si la v.a. no cumple el supuesto de normalidad. Se suele denominar estandarización (o normalización, aunque normalización a menudo refiere a otra transformación \(\frac{X — X_{min}}{X_{max}-X_{min}}\) que da un valor entre 0 y 1).
Nota
Estandarización no es para transformar una distribución a una distribución normal. Si la distribución antes de estandarización no es normal, la distribución después de la estandarización tampoco es normal.
Para algunos ML algoritmos o modelos estadísticos, estandarización es importante porque lleva diferentes variables a una escala comparable, incluso si la v.a. no cumple el supuesto de normalidad.
Regla Empírica 68-95-99.7
Si \(X \sim \cal{N}(\mu,\sigma^2)\), entonces:
\(\begin{array}{lll} P(\mu-\sigma < X < \mu+\sigma) & = & 0.68\\ P(\mu-2\sigma < X < \mu+2\sigma) & = & 0.95\\ P(\mu-3\sigma < X < \mu+3\sigma) & = & 0.997\\ \end{array}\)
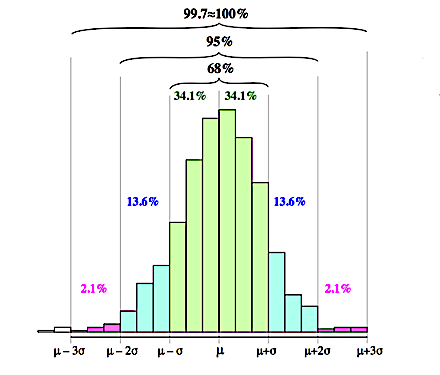
Muy útil para la detección de outliers, bajo el supuesto de normalidad. Por ejemplo, una heurística convencional es considerar un valor fuera de \(3\sigma\) de la media como un outlier.